Customer Case Study: Developing a High-Performance Application on an Embedded Edge AI Device

One of the challenges in building embedded AI applications is taking it from machine learning research environment all the way to a full application deployed on an embedded host in the real world.
Recently, a Hailo customer has asked us to bring up such an application. Our Applications Team thought it was a good opportunity to share the development process and its outcome as an AI case study and a typical example of advanced edge AI development.
The Embedded AI Scenario
Our customer required real-time high-accuracy object detection to run on a single video stream using an embedded host. The required input video resolution was HD (high definition, 720p).
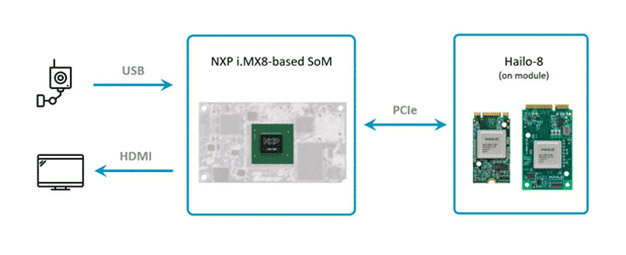
The chosen platform for this project is based on NXP’s i.MX8M ARM processor. The Hailo-8 AI processor is connected to it as an AI accelerator.
The object detection model that was selected for this application is YOLOv5m. This modern object detection deep learning model allows both high detection accuracy and high throughput when running on the Hailo-8 device. It reaches an accuracy of 41.7mAP on the COCO validation set.
The requirements posed by our customer are by no means an easy ask. As embedded devices have strict power, heat dissipation and space constraints (you can read more about those in our paper on edge AI power efficiency), traditional processors designed for them are small and not very powerful. In most cases, such processors simply can’t support large, compute- or parameter-intense neural network models, processing high-resolution video in real time (or at about 30 FPS).
However, using such an embedded host with an AI accelerator like the Hailo-8, allows you to overcome these limitations and achieve an embedded platform which does the job and is highly power efficient. A setup like the one we use here can be the base for developing a smart camera for both outdoor and indoor use-cases. Such intelligent cameras are useful across many industries and domains, such as Smart City, Smart Home and Industry 4.0.
Not Just AI Acceleration, but a Complete Computer Vision Solution
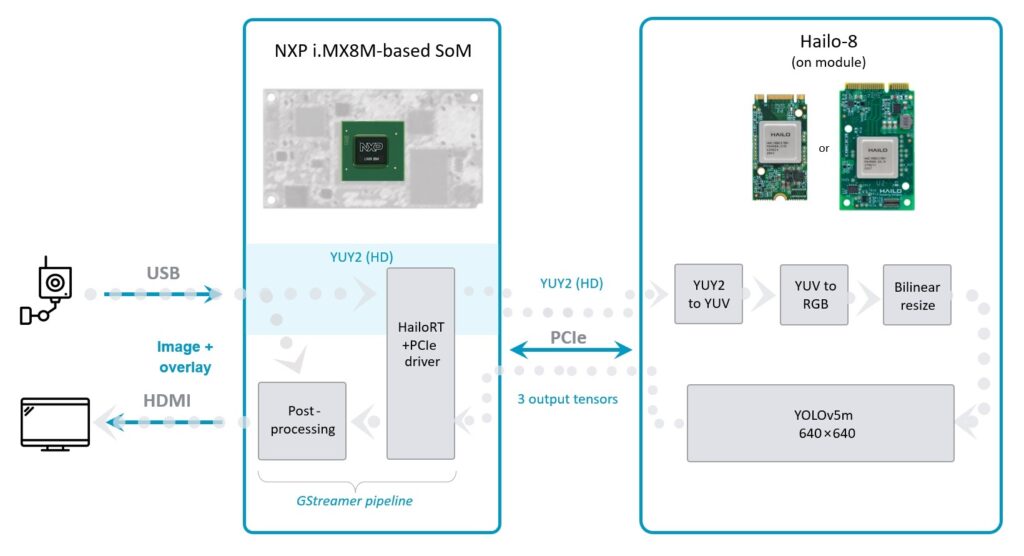
Although the i.MX8M is a capable host, processing and decoding real-time HD video is bound to utilize a lot of the CPU’s resources, which may eventually reduce performance. To solve this problem, most of the vision pre-processing pipeline has been offloaded to the Hailo-8 device in our application.
The camera sends the raw video stream, encoded in YUV color format using the YUY2 layout. The data passes through Hailo’s runtime software library, called HailoRT, and through Hailo’s PCIe driver. The data’s format is kept unmodified, and it is sent to the Hailo-8 device as is.
Hailo-8’s NN core handles the data preprocessing, which includes decoding the YUY2 scheme, converting from the YUV color space to RGB and, finally, resizing the frames into the resolution expected by the deep learning detection model.
The Hailo Dataflow Compiler supports adding these pre-processing stages to any model when compiling it. In this case, they are added before the YOLOv5m detection model.

The outputs of the object detection model are sent back to the host, which runs the post-processing stage of the model and draws the overlay boxes on top of each frame.

Integrating into the Embedded Software Stack
The entire software data flow is managed by the GStreamer framework, which is a common Linux framework for video processing. In this case, it controls the full pipeline, including receiving the video stream from the camera, interacting with the Hailo-8 device, and drawing the output video frames with the detections overlay.
Hailo GStreamer elements, which are the base for many of the application in our TAPPAS Application Toolkit, wrap the HailoRT library and allow the integration of the Hailo accelerator with the GStreamer framework. The pipeline runs in real time (30 FPS) on an embedded Yocto Linux OS.
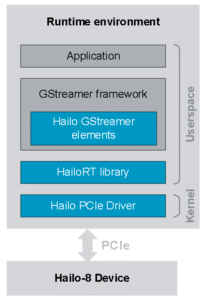
This approach allows to easily and seamlessly build applications from existing building blocks using a well-known framework. What is truly great is that you do not have to compromise on achieving impressive performance even if you are using smaller hosts and platforms.
Putting It All Together
When you run the application, the compiled model that contains the pre-processing and the YOLOv5m deep learning model is being loaded into the Hailo-8 device. Video frames start to go through the GStreamer pipeline to the Hailo-8 device and back, and the detections are shown on the display.
Building an embedded edge AI product cannot be considered done when the model is trained, and even not when the model is compiled for the target accelerator. The development and deployment of the embedded runtime application that runs the model might be challenging and requires choosing the right tools for the task. This is why we continue to focus on developing software tools that provide solutions for building the full end-to-end pipelines on the Hailo-8 device, bringing real-world use cases to life!