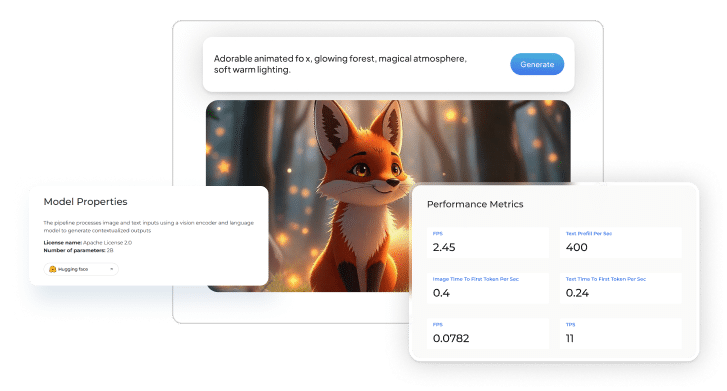
概要
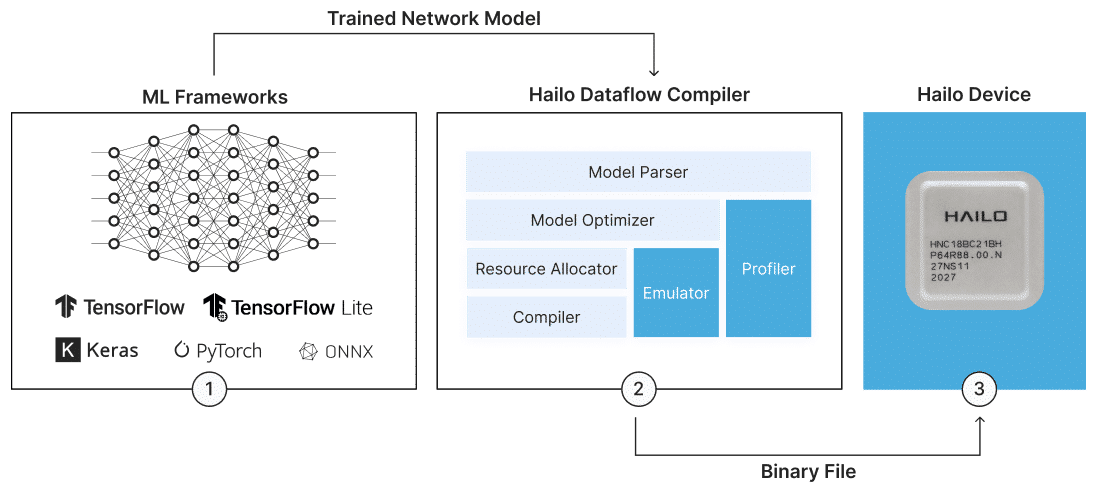
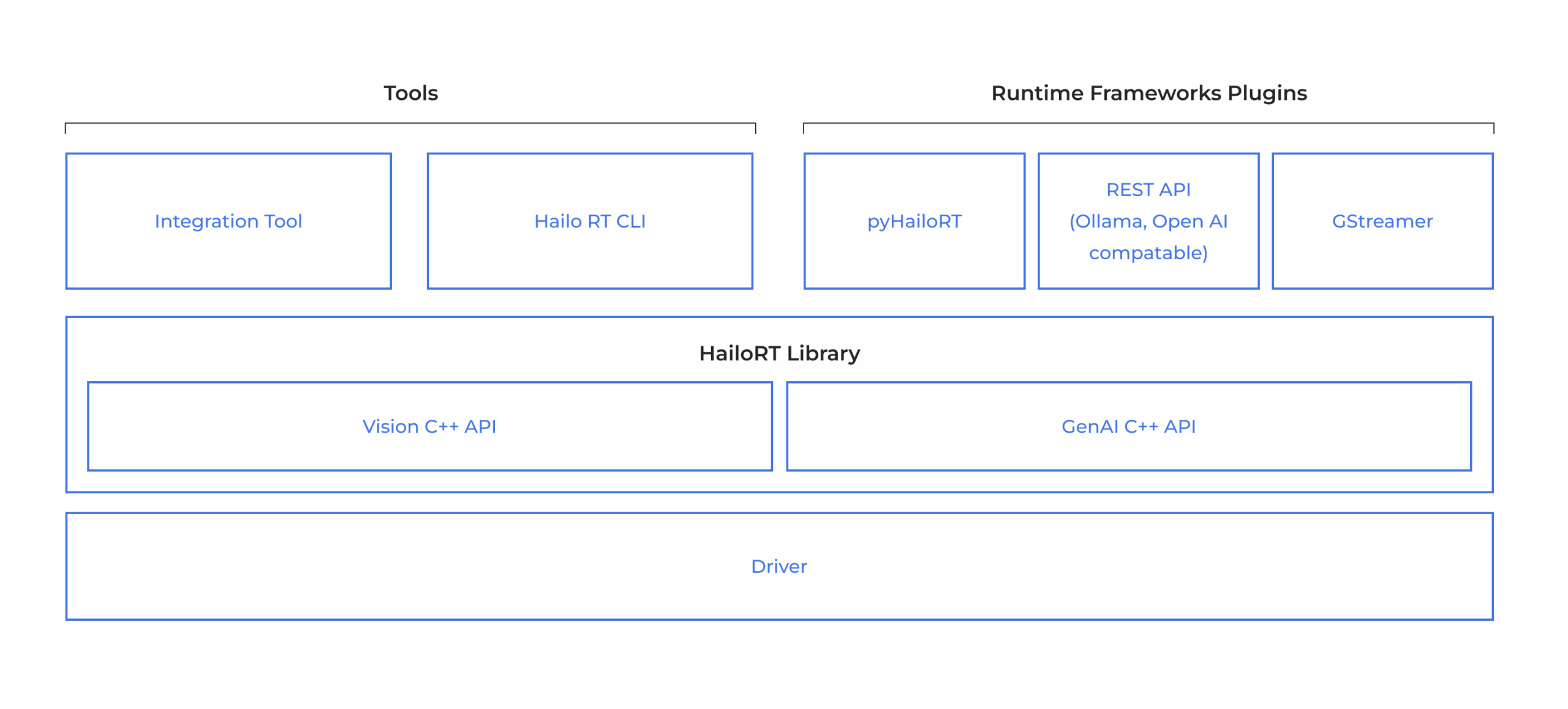
Hailoのデバイスには、深層学習モデルのコンパイルおよび本番環境におけるAIアプリケーションの実装を可能にする包括的なAI Software Suiteが付属しています。このモデル構築環境は、一般的なMLフレームワークとシームレスに統合でき、既存の開発エコシステムにおいてスムーズかつ容易な導入を実現します。ランタイム環境は、Hailoのビジョンプロセッサをサポートし、x86やARMベースのホストプロセッサへの統合および展開を可能にします。これにより、HailoのAIアクセラレータを活用できます。