AI Object Detection on the Edge: Making the Right Choice

When choosing an AI object detection network for edge devices, there are many factors you should consider: compute power, memory resources, and many more. Which ones? This blogpost outlines everything you need to know when choosing an object detection network for your edge application. But remember, the Hailo-8 processor provides high-performance computing on the edge and can have a prominent role in improving the accuracy of the network.
Object detection in computer vision classifies and localizes all the objects in an image. It is widely used in Automotive, Smart City, Smart Home, and Industry 4.0 applications, among others.
However, running AI object detection on the edge has some drawbacks as well. One reason is that compute and memory are limited on edge devices, which limits the choice of the object detection network. For example, the standard mobile/CPU regime defined in the deep learning literature usually allows approximately 800M FLOPS per frame. Under this regime, the chosen object detector would need to be highly efficient and small, for example, MobileNet-v2-SSD (760M FLOPS for ~0.1MPixel input). Another set of constraints in edge devices is power consumption and heat dissipation, which also limits the processing throughput.

However, running object detection on the edge has some drawbacks as well. One reason is that compute and memory are limited on edge devices, which limits the choice of the object detection network. For example, the standard mobile/CPU regime defined in the deep learning literature usually allows approximately 800M FLOPS per frame. Under this regime, the chosen object detector would need to be highly efficient and small, for example, MobileNet-v2-SSD (760M FLOPS for ~0.1MPixel input). Another set of constraints in edge devices is power consumption and heat dissipation, which also limits the processing throughput.
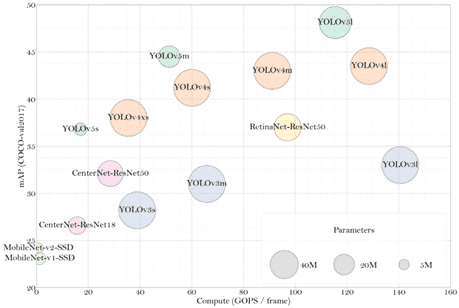
Figure 2 – compute/accuracy tradeoff for popular object detectors (sources appended at the end)
For these reasons, in recent years we have seen dramatic increase in the demand for AI accelerators at the edge. An AI accelerator is specialized hardware designed specifically for inference of deep learning object detectors with speed and efficiency. State-of-the-art AI accelerators have enough computing power (measured in TOPS, or Tera Operations Per Second) to run the most accurate object detectors in real time while consuming only a few Watts of power. However, even such specialized hardware usually requires an educated choice of the optimal object detector.
Edge Object Detection Networks
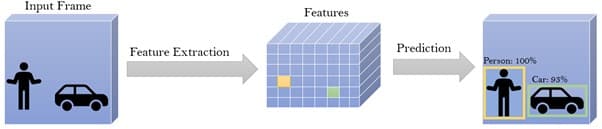
The main concept behind deep learning object detectors is that every object has a unique set of features. These features are extracted from the input frame using an object detection neural network or convolutional neural network (CNN) and then used to classify an object in a specific location in the frame. For example, a CNN processing an input frame with a car located in pixel will generate a set of features associated with this specific class in location of the feature map.
Object identification architectures can be divided into single-stage (for example: SSD, YOLO and CenterNet) and two-stage (Fast/Faster-RCNN). Chronologically, two-stage architectures were the first to appear. In these, the task is divided into two parts: generating class-agnostic box proposals for the input frame (localization without classification) and processing each proposal for classification and the final regression of the predicted box (mostly classification). The features that are extracted for prediction of the first stage are reused as inputs for the second stage as well. Single-stage architectures, on the other hand, perform localization and classification concurrently, using only a single stage for both tasks. In these networks, a single forward-pass is used to predict bounding boxes and class probabilities directly from the input image.
Choosing an Object Detection Network
There are multiple criteria for choosing the optimal object detection network for your edge device. As a rule, single-stage detectors are more computationally efficient than two-stage architectures, which usually makes them a better choice for the edge. For example, Faster-RCNN-ResNet50 has an accuracy of 38.4mAP on COCO val2017 with 520G FLOPS per frame while YOLOv5m achieve 44.5mAP on the same dataset with only 51.3G FLOPS per input frame. Among single-stage object detectors we can also see a big variation in the memory footprint. For instance, YOLOv5s with only 7.3M parameters vs. YOLOv3 with 62M parameters and similar accuracy.
Reduced memory and compute of a network usually results in lower power consumption and higher FPS, so both parameters should be taken into consideration. Another factor to consider is the post-processing. Since NMS (Non-Maximum Suppression) is not supported by many edge devices, running an architecture that does not require NMS, like CenterNet, can reduce host utilization and increase the overall FPS of the application.
Next, we review some of the major single-stage architectures for edge-based AI object detection:
- SSD: a very popular and lightweight architecture is the Single Shot multi-box Detector (SSD). SSD is based on anchors – predefined boxes used for prediction. The network predicts the class probabilities and the best anchor match for each object with additional small fixes for the predefined box. Predictions are aggregated from different feature maps within the network to improve the multi-scale capabilities of the network. The main idea is that the large feature maps would have enough resolution to make accurate predictions for small objects and the small feature maps would encompass enough receptive field to make accurate predictions for large objects1. The final proposals from all the feature maps are aggregated and feed an NMS block that outputs only the surviving final predictions2.
- YOLO: perhaps the most popular deep learning family of detectors, YOLO – You Only Look Once, is an anchor-based single stage object detector with excellent performance, despite being heavily parameterized. YOLO has many variants and versions, but the unique concept of “objectness” is common across the entire family of models. It states that the set of features extracted by the CNN will be used to predict confidences for different anchors in each spatial location. Because the objectness is common to all classes, this provides a conceptual separation between localization and classification predictions. Like SSD, YOLO uses an NMS to suppress most proposals and output only the surviving boxes and class probabilities. In YOLOv5 there is also a unique box decoding optimization, which allows to replace the expensive exponent function with a relatively cheap shift operation and so allows the architecture to run very fast even without a strong host. For example, a Hailo-8 AI Processor device connected to a Celeron N4100 host can run YOLOv5m at over 30 FPS.
- CenterNet is an efficient single-stage anchorless object detector. Anchorless architectures do not employ predefined boxes, but rather the box dimension is predicted directly from the generated feature map. Each object is represented by the center point of its bounding box and the network predicts keypoint heatmaps of all box centers. To suppress irrelevant boxes, we simply extract local peaks from the keypoint heatmap. This is done without NMS, which makes the suppression process very efficient and fast. In anchorless architectures, priors of anchors and hyperparameters are reduced from your model, which means less tunning for a new dataset.
In conclusion, the choice of an AI object detection network to run on your edge device includes many parameters that, for optimal performance, need to be considered such as the compute and memory resources. Hailo-8 is flexible and supports multiple object detection meta-architectures efficiently. So next time you need to choose an object detector for your application be sure to detect the right one!
Notes
- RGB image 300x300x3
This feature is what makes SSD run very fast on many AI accelerators, for example, Hailo-8 runs MobileNet-v1-SSD at over 1000 FPS (processing capability which can be leveraged to process multiple streams or to upscale input resolution to improve accuracy). ↩︎ - Read more about NMS here ↩︎
Useful Links
YOLOv5, YOLOv4/3, TF-OD-model zoo, GluonCV, MMDetection, Detectron2
References
Bochkovskiy, A., Wang, C.-Y., Hong-Yuan, & Liao, M. (2020). YOLOv4: Optimal Speed and Accuracy of Object Detection. Tech Report.
Girshick, R. (2015). Fast R-CNN. ICCV.
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR.
Lin, T.-Y., Dollár, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017). Feature Pyramid Networks for Object Detection. CVPR.
Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal Loss for Dense Object Detection. ICCV.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A. C. (2016). SSD: Single Shot MultiBox Detector. ECCV.
Redmon, J., & Farhadi, A. (2018). YOLOv3: An Incremental Improvement. Tech Report.
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection. CVPR.
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. NeurIPS.
Tan, M., Pang, R., & Le, Q. V. (2020). EfficientDet: Scalable and Efficient Object Detection. CVPR.
Tian, Z., Shen, C., Chen, H., & He, T. (2019). FCOS: Fully Convolutional One-Stage Object Detection. ICCV.
Zhou, X., Wang, D., & Krähenbühl, P. (2019). Objects as Points. Tech Report.