Edge ML Deep Dive: Why You Should Use Tiles in Squeeze-and-Excite Operations

This blog post presents the Tiled Squeeze-and-Excite (TSE) – a method designed to improve the deployment efficiency of the Squeeze-and-Excite (SE) operator to dataflow architecture AI accelerators like the Hailo-8 AI processor. It is based on our latest paper, which has recently been accepted by the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) for the NeurArch Workshop!
We developed TSE with the goal of accelerating the runtime of neural network architectures that include SE without requiring users to change or re-train their model. This work is part of a larger bag-of-tricks for model optimization prior to inference. Some of these methods have no effect on the model (e.g., batch norm folding), some have an only numeric effect but preserve the architecture (e.g., quantization) and some change the architecture to optimize performance. TSE falls in the latter category.
What Is Squeeze-and-Excite?
Squeeze-and-Excite (SE) (Hu, et al., 2017), is a popular operation used in many deep learning networks to increase the accuracy with only a small increase to compute and parameters. The operation is part of a more general family of operations called channel attention. In channel attention we re-calibrate each channel of a given tensor according to the tensor’s data, which means that for every input we use different calibration factors.
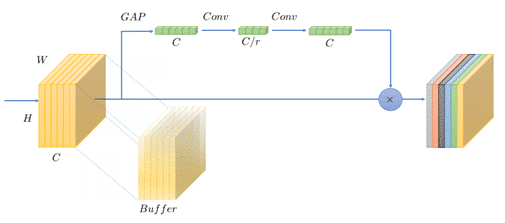
Unlike the convolution, which uses only a small receptive field, SE uses global context and operates in two steps. We first squeeze the input tensor by means of global average pooling (GAP). For an input of shape HxWxC the GAP generates a vector 1x1xC by averaging over each channel separately. The second step – excitation, processes the input vector produced by the GAP and produces a vector of the same length with values normalized to [0,1]. These values are then multiplied by the input tensor which creates the desired scaling property of channel attention.
Although many SE variants were proposed over the years, vanilla SE remains the most popular due to its simplicity and effectiveness. For example, it improves the Top-1 accuracy of ResNet-50 on ImageNet by 1.02, while adding only 0.01 GFLOPs and 2.5M parameters (Hu, et al., 2017). SE is used by many modern CNN architectures like EfficientNets (Tan & Le, 2019), RegNets (Radosavovic, et al., 2020), MobileNet-v3 (Howard, et al., 2019) and shows accuracy gains for downstream tasks as well (like object detection and semantic segmentation).
Adding accuracy for “free” is attractive especially for edge devices with a limited compute budget and, indeed, the SE operation is popular in efficient architectures aimed for the mobile regime. So, what is the downside of using SE?
In Comes Tiled Squeeze-and-Excite
Dataflow AI accelerators like the Hailo-8 AI processor, leverage the fixed flow of data in DNN to optimize power and throughput. It uses inter-layer pipelining (locally cached memory) and minimize the accesses to energy consuming memory levels (for example, off-chip DRAM). To that end, it tries to discard unused data as fast as possible and store only the necessary data to carry out the calculation. For example, it can discard the input row of a tensor after processing the first rows of the output in a convolutional layer. The GAP operation in SE challenges the dataflow architecture by stopping the pipeline and forcing a full input buffering to calculate the output. That is because the input tensor is multiplied by the GAP output, and to calculate the GAP we need the entire input tensor.
To quantify this effect, we introduce a new metric, termed “pipeline buffering”, to represent the minimum memory required by the SE operation. To reduce pipeline buffering, we suggest Tiled Squeeze-and-Excite.
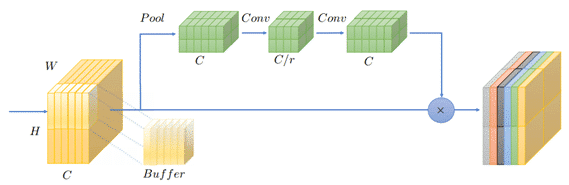
TSE works on input data tiles and therefore enables buffering of tiles instead of the full input tensor. In TSE, we mimic the SE operation in non-overlapping tiles of the input tensor. The Excite step of the SE remains the same and works exclusively on each tile, while the Squeeze step averages on a smaller portion of the data.
In extensive experiments on a variety of different architectures and tasks, we have shown that TSE can be used as a drop-in-replacement for the costly SE operation, enabling efficient deployment on AI dataflow accelerators without sacrificing the accuracy gains. An example of this is a 73% reduction in pipeline buffering for EfficientNet-B2 with the same level of accuracy on ImageNet.
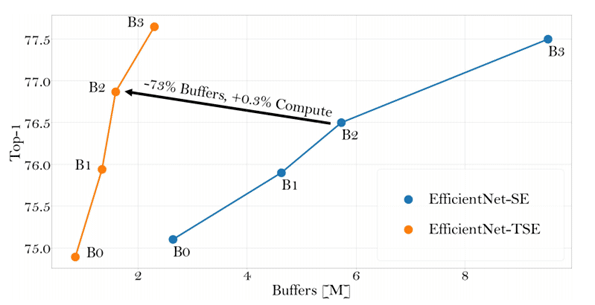
To avoid retraining the network, we need to use the original weights (from the network trained with SE) in the new TSE structure. In our experiments, we showed that this assignment incurs very small degradation of around 0.5% on ImageNet classification networks. We also observed that SE blocks at the beginning of the network are much less sensitive, and that averaging on seven rows of the input tensor is a good estimator for the average value of the entire tensor. This conjecture implies that the image’s local context (for example, the seven upper rows) has enough representative information to describe the entire global context (the full image).
Another important feature of TSE is that it works not only for classification (with low input resolution) but also works surprisingly well for downstream tasks like object detection or semantic segmentation, which work on high-resolution inputs.
How TSE Is Implemented in the Hailo Toolchain?
The Hailo Dataflow Compiler includes several stages for compiling deep learning models into the Hailo-8. First, we parse the trained model from TF/ONNX into Hailo’s internal representation. The second stage is to produce an optimized model with accelerated performance and minimize accuracy degradation. Our model optimization toolkit includes TSE and other methods to reduce quantization noise such as Equalization (Meller, et al., 2019) and IBC (Finkelstein, et al., 2019) and to optimize over the model performance. It also supports quantization-aware fine tune (QFT), which leverages back propagation to train the quantized model to reduce quantization noise and can also reduce any degradation caused by the TSE. Check out the Hailo Model Zoo for a demonstration of the optimization for state-of-the-art deep learning models such as YOLOv5 and CenterPose. At the third and final stage we compile the optimized model into a binary file that can be used for inference on the Hailo-8 chip.

This blog post is part of an Edge Machine Learning Deep Dive series. Subscribe to stay tuned for future installments.
In the meantime, to learn more about Machine Learning on edge devices and the Hailo architecture, read this paper and others on our resources page and visit our Developer Zone, where you will find benchmarks, out-of-the-box applications and models and more!
Bibliography
Finkelstein, A., Almog, U. & Grobman, M., 2019. Fighting Quantization Bias With Bias. CVPR.
Howard, A. et al., 2019. Searching for MobileNetV3. ICCV.
Hu, J. et al., 2017. Squeeze-and-Excitation Networks. CVPR.
Radosavovic, I. et al., 2020. Designing Network Design Spaces. CVPR.
Tan, M. & Le, Q. V., 2019. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ICML.
Tan, M., Pang, R. & Le, Q. V., 2020. EfficientDet: Scalable and Efficient Object Detection. CVPR.
Vosco, N., Shenkler, A. & Grobman, M., 2021. Tiled Squeeze-and-Excite: Channel Attention With Local Spatial Context. Arxiv.