






Overview
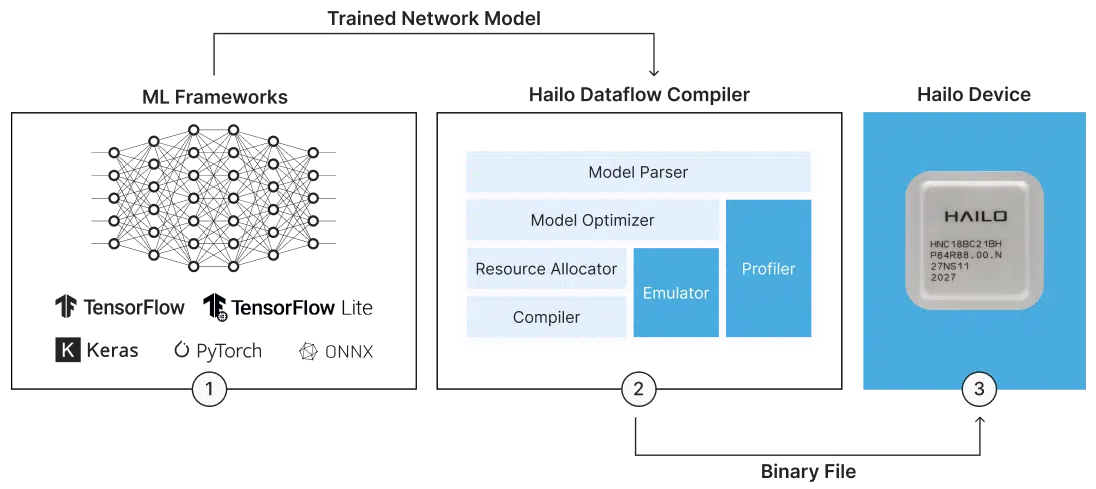
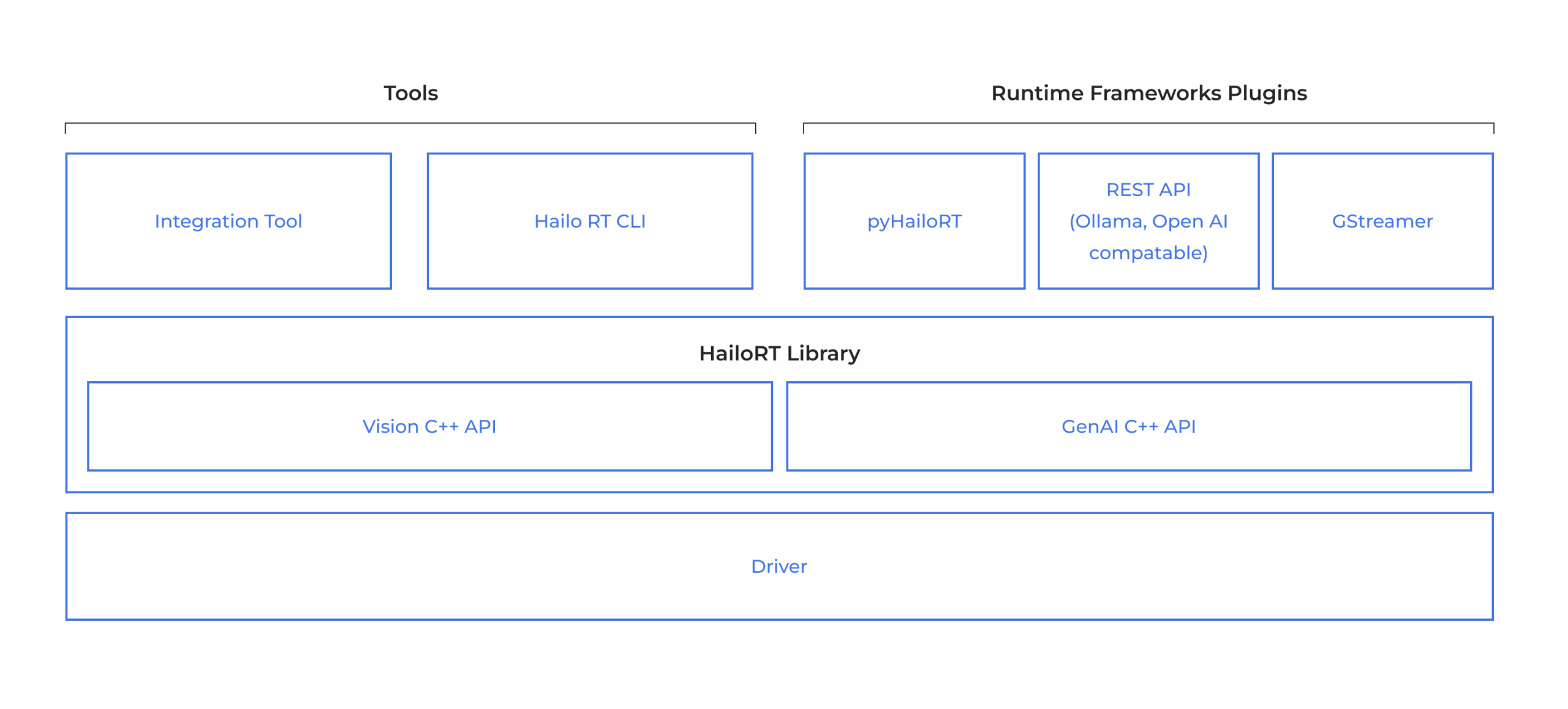
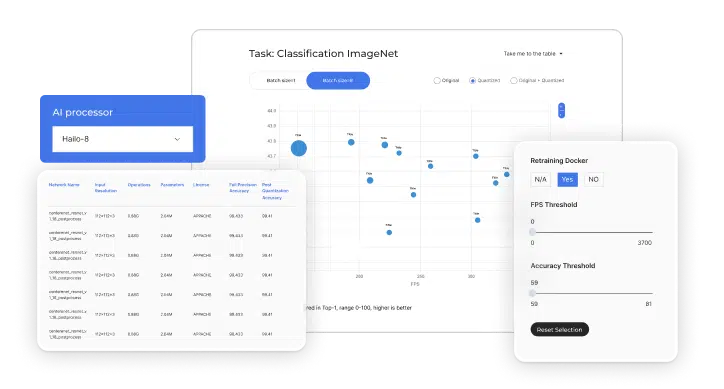
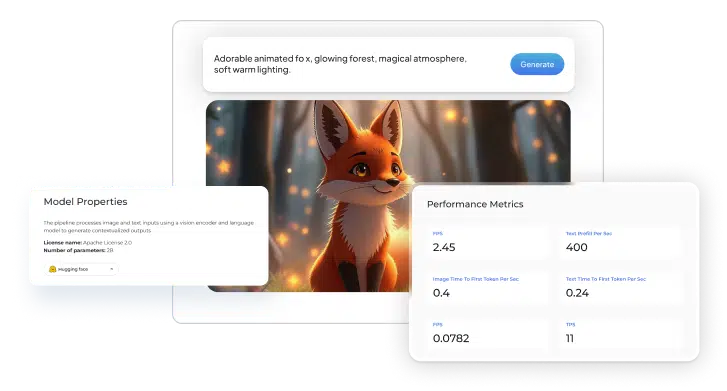
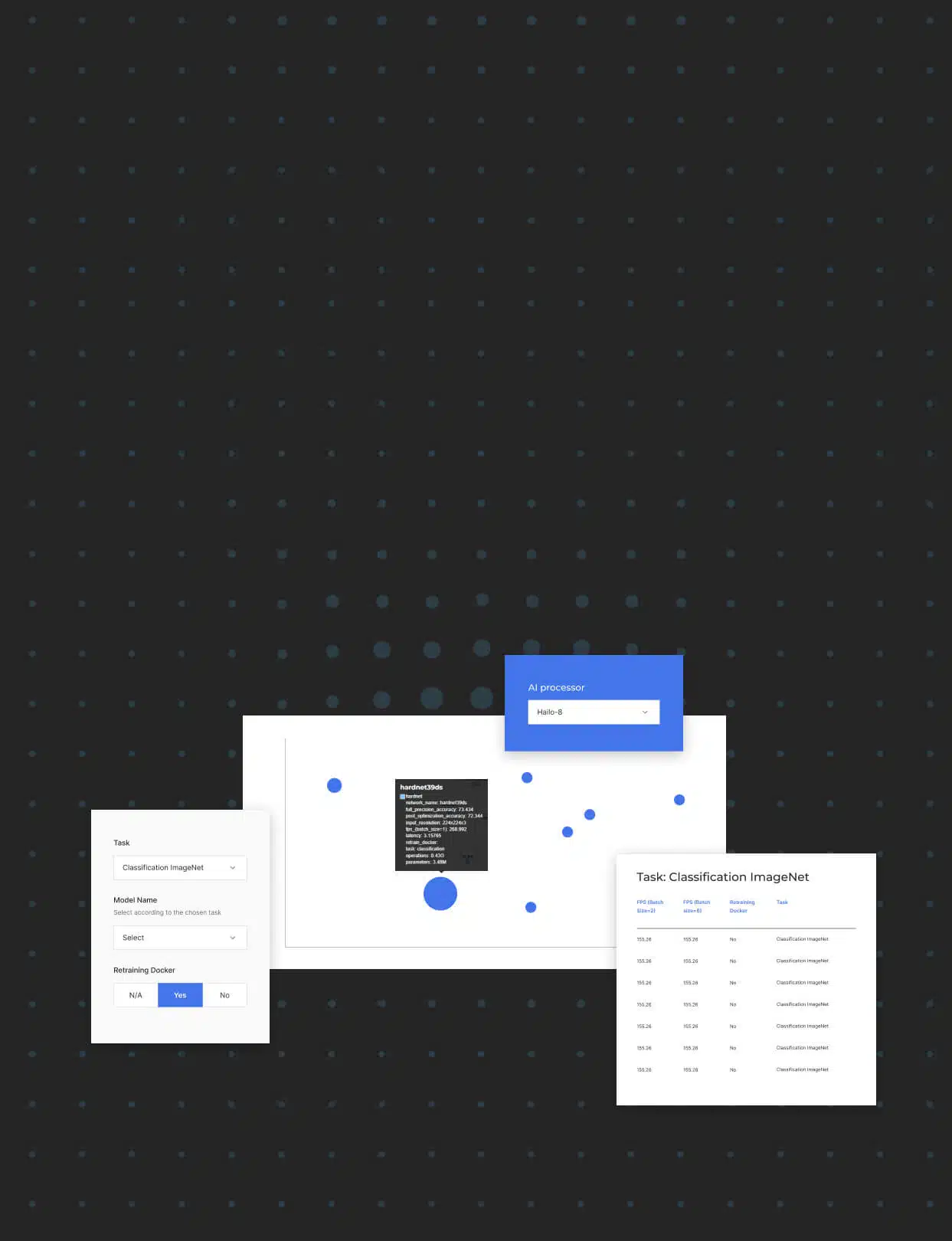
Hailo devices are accompanied by a comprehensive AI Software Suite that enables the compilation of deep learning models and the implementation of AI applications in production environments. The model build environment seamlessly integrates with common ML frameworks to allow smooth and easy integration in existing development ecosystems. The runtime environment supports Hailo’s vision processors, and enables integration and deployment in host processors, such as x86 and ARM based products, when utilizing Hailo’s AI accelerators.