
概述
Hailo设备配有全面的人工智能软件套件,可实现深度学习模型编译,并在生产环境中实施人工智能应用。模型构建环境与通用机器学习框架无缝集成,从而在现有的开发生态系统中实现平稳、简单且快速的集成。运行时环境支持Hailo的视觉处理器,在使用Hailo的人工智能加速器时,能够实现在主机处理器(如基于x86和ARM的产品)中的集成和部署。
Hailo设备配有全面的人工智能软件套件,可实现深度学习模型编译,并在生产环境中实施人工智能应用。模型构建环境与通用机器学习框架无缝集成,从而在现有的开发生态系统中实现平稳、简单且快速的集成。运行时环境支持Hailo的视觉处理器,在使用Hailo的人工智能加速器时,能够实现在主机处理器(如基于x86和ARM的产品)中的集成和部署。

Model Zoo Vision:TensorFlow和ONNX中各种常见的先进预训练模型和任务。
Model Zoo GenAI:精心整理的预训练生成模型集合,可通过CLI和REST API访问。
Dataflow Compiler:用于为Hailo设备离线编译和优化用户模型。
Hailo设备配有与现有深度学习开发框架无缝整合的全面数据流编译器,从而在现有的开发生态系统中实现平稳而简单的集成。
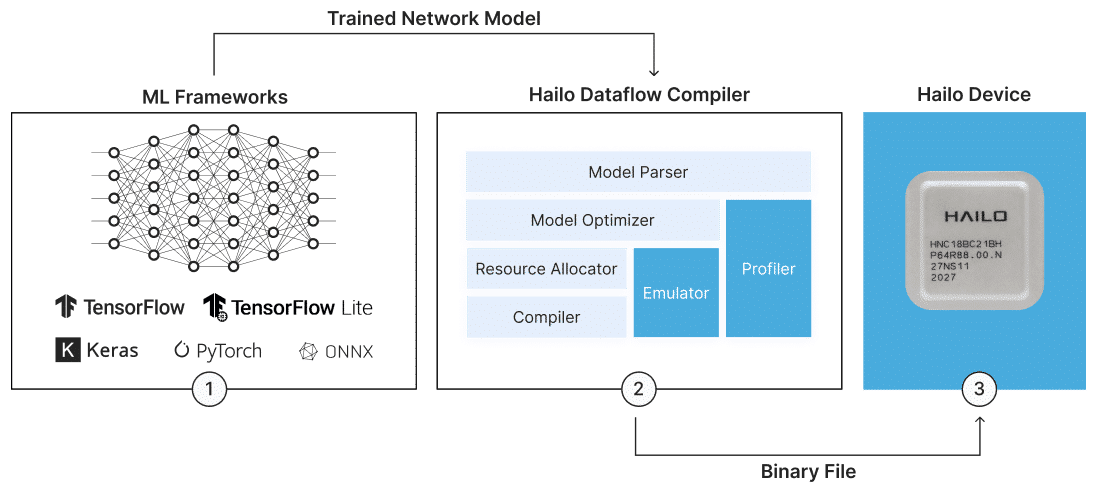
从行业标准框架到Hailo可执行格式的模型转换
采用最先进的量化方案,对内部表征的模型优化
自动资源分配,满足用户在FPS、延迟、功耗等方面的需求
专用的深度学习编译器,将模型编译为Hailo二进制
在Hailo目标设备上加载二进制及运行推断
同时支持独立推断(可直接访问设备)和Tensorflow集成推断(与现有环境轻松集成)
提供芯片行为位精确模拟的模拟器
提供芯片性能估计(如FPS、功率和延迟)的分析器
HailoRT是一款生产级、轻量级且可扩展的运行时软件,提供功能强大的库,具有直观的API,以实现优化的性能。我们的人工智能软件开发工具包能让开发者在生产中为人工智能应用构建简单快速的管道,也适用于评估和原型设计。它可在Hailo人工智能视觉处理器上运行;在使用Hailo人工智能加速器时,它可在主机处理器上运行,并能通过一个或多个Hailo设备实现高吞吐量的推理。HailoRT可以通过Hailo Github作为开源软件使用。
多主机架构支持 – 支持x86和ARM架构
多操作系统支持,如Linux、Windows和Android
人工智能应用的灵活接口 – C/C++和Python API
与设备和管道的轻松集成 – 标准框架支持:
GStreamer、ONNX运行时、Ollama和其他框架
支持多视频流 – 同时处理多个视频流
支持最多16个Hailo人工智能加速器设备的高吞吐量推理
无缝接口控制,用于与Hailo神经网络核的双向控制和数据通信
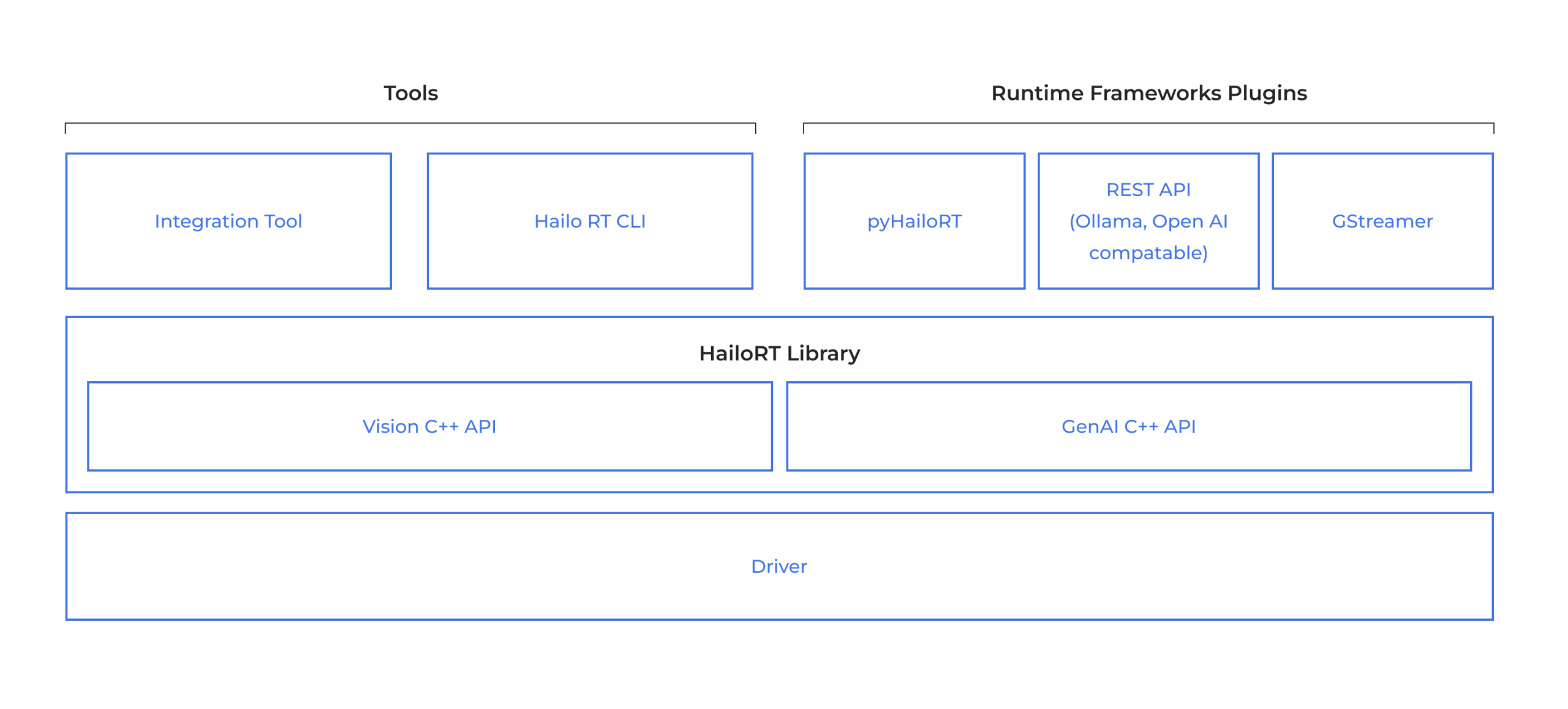
用于与Hailo人工智能加速器的硬件集成验证流程
命令行应用,用于控制Hailo设备、在设备上运行推理以及收集推理统计数据和设备事件
用户空间,运行时,健壮的C/C++ API,用于控制及与Hailo设备之间的数据传输
Hailo提供两个专门的Model Zoo库,旨在加快在各种人工智能工作负载上的开发进程:
Hailo Model Zoo Vision为各种计算机视觉任务提供预训练深度学习模型,在Hailo设备上进行快速原型设计。附带的GitHub库使用户能够使用广泛支持的模型和架构来轻松重现Hailo公布的性能基准测试结果。
GenAI提供一个精心挑选的预编译生成式模型集合,其中包括大型语言模型、视觉语言模型、自动语音识别、稳定扩散等。这些模型可通过CLI和REST API访问,与OpenAI和Ollama完全兼容,因此是与生成式人工智能工作流程进行快速集成的理想之选。
TensorFlow和ONNX中各种常见的先进预训练模型和任务
模型细节,包括在Hailo设备上测量的全精度准确度与量化模型准确度
为每个模型发布一个编译后的二进制HEF文件,供HailoRT及示例应用加载。
为了支持各类人工智能应用,Hailo提供两款专门设计的Model Explorer工具:一款用于计算机视觉模型,另一款用于生成式人工智能模型,每款工具都旨在帮助开发者做出明智决策并加快部署进程。
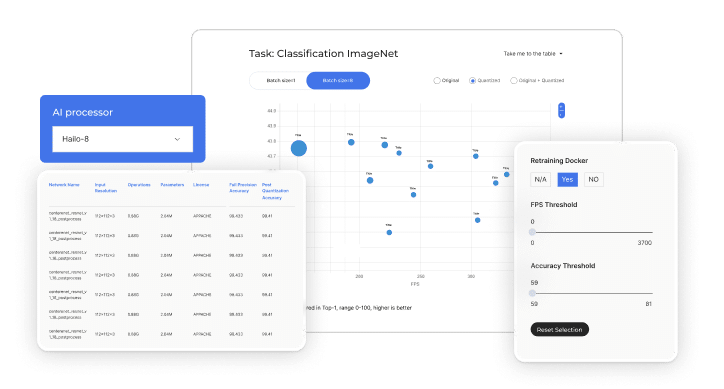
Model Explorer – Vision使用户能够浏览、筛选并评估来自Hailo Model Zoo的深度学习模型。它具有交互式界面,配备诸如Hailo设备类型、任务、模型名称、每秒帧数和准确度等筛选选项,帮助您为实时视觉工作负载选择最合适的模型。
每个模型都经过预训练,并包含即用型二进制文件(HEF文件),与Hailo工具链及应用套件兼容。模型支持TensorFlow和ONNX格式,可以进行重新训练、编译以及部署,以便在Hailo设备上快速进行原型开发。
模型选择会综合考虑多种因素,例如推理速度、准确度、模型大小以及硬件兼容性。由于推理速度无法根据静态属性(如FLOPS或参数数量)进行可靠预测,因此Vision Model Explorer提供真实硬件基准,以指导基于性能的决策。
The Model Explorer GenAI使用户能够按照产品和任务类型来浏览预编译的生成式人工智能模型。所有支持的模型都列在Hailo Model Zoo GenAI中,该库包含运行这些模型所需的一切内容,例如CLI工具、REST API以及与OpenAI和Ollama兼容的集成支持。
每个模型都经过预训练,并包含即用型二进制文件(HEF文件),与Hailo工具链及应用套件兼容。模型支持TensorFlow和ONNX格式,可以进行重新训练、编译以及部署,以便在Hailo设备上快速进行原型开发。
模型选择会综合考虑多种因素,例如推理速度、准确度、模型大小以及硬件兼容性。由于推理速度无法根据静态属性(FLOPS或参数量)进行可靠预测,因此Vision Model Explorer提供真实的硬件基准,以指导基于性能的决策。
Hailo提供一套参考应用示例,旨在简化边缘人工智能应用的开发和部署。这些示例展示如何利用GStreamer和预训练人工智能任务来构建实时管道,为使用Hailo人工智能加速器的开发人员提供一个实用的起点。这些应用旨在突出Hailo设备的高吞吐量和功率效率,同时展示与Hailo运行时和系统架构进行集成的最佳实践。它们用作即用型模板,可以进行个性化设置和扩展,以适应特定的用例,从而帮助缩短开发时间并加快上市。
检测和分类图像中的对象是计算机视觉中的一项关键任务,称为对象检测。在COCO数据集(用于目标检测的流行数据集)上训练的深度学习模型在性能和准确性之间提供不同的权衡。例如,通过在Hailo-8上运行推理,YOLOv5m模型实现了218 FPS和42.46mAP准确度,SSD-MobileNet-v1模型实现了1055 FPS和23.17mAP准确度。COCO数据集包含80个独特的对象类别,适用于一般使用场景,包括室内和室外场景。
车牌识别(LPR)管道,也称为自动车牌识别(ANPR),通常用于智能交通系统(ITS)市场。此示例应用演示了复杂管道中3个不同网络之间的自动模型切换。并行运行用于车辆检测的YOLOv5m模型、用于检测车牌的YOLOv4-tiny模型和用于文本提取的lprnet模型。
在我们的车牌识别人工智能博客文章中阅读更多内容
多流对象检测可用于不同行业的各种应用,包括智慧城市交通管理和 智能交通系统(ITS)等复杂应用。您可以使用自己的对象检测网络,也可以依赖YOLOv5m等预构建模型,这些模型都是在COCO数据集上训练的。值得注意的是,这些模型提供了独特的功能,例如平铺,该功能利用Hailo的高吞吐量,通过将高分辨率图像(FHD、4K)划分为更小的图块来处理它们。事实证明,处理高分辨率图像在小物体大量存在的拥挤场所和公共安全应用中特别有用,例如零售和智慧城市的人群分析等用例。
跨不同流的多人重新识别对于安全和零售应用至关重要。这包括多次识别特定人员,无论是在一段时间内的特定位置,还是沿着多个位置之间的路径。此示例应用演示了YOLOv5s和repvgg_a0_person_reid深度学习模型的神经网络模型切换,这些模型使用Hailo的数据集在具有基于推理的决策的复杂管道中进行训练。这是使用模型调度程序来实现的,模型调度程序是一种用于模型切换的自动工具,可以在运行时同时处理多个模型。
单幅图像的深度估计通过估计2D图像的深度或距离信息并将其转换为3D映射的能力来实现。它使汽车摄像头能够更好地了解与物体的距离,帮助工业检测摄像头完成缺陷检测和质量控制等任务,并可通过提供更详细的空间信息来提高安全摄像头人员检测的准确性。
在此示例中,我们使用在NYUv2数据集上训练的fast_depth深度学习模型,该模型预测具有相同形状的输入帧的距离矩阵(每个像素的不同深度)。
实例分割任务是合并对象检测(包括识别和分类对象)和语义分割(将特定类别分配给各个像素)的功能,为给定场景中的每个对象生成不同掩码的过程。当边界框缺乏定位精度以及应用需要对象之间的像素级区分时,此任务变得尤为重要。该应用利用yolov5seg或YOLACT架构,需要使用COCO数据集来训练这些模型。
姿态估计是一种计算机视觉技术,可检测和跟踪图像或视频中的人体姿势。从识别家中或工厂车间的紧急情况,到分析客户行为以获得更好的业务成果。它涉及定位人体的不同部位,例如头部、肩膀、手臂、腿部和躯干,并估计它们在3维空间中的位置和方向。该管道包括在COCO数据集上预训练的centerpose模型的组合。
面部检测是利用对象检测网络来检测特定面部对象的常见任务。面部检测网络使用WIDER数据集进行训练,其输出是帧中所有人脸的框预测。此应用演示了如何裁剪检测器生成的感兴趣区域(ROI)并馈送到第二个网络来预测每个预测人脸的面部标志。面部标志是分析面部朝向、结构等的重要特征。
为了增强Hailo设备处理大输入分辨率的处理能力,我们可以将输入帧划分为多个图块,并在每个图块上单独运行对象检测器。例如,考虑一个在4K输入帧中占据10×10像素的对象。对于640×640检测器(例如YOLOv5m)来说,该对象仅包含1个像素的信息,因此几乎无法检测到。为了解决这一挑战,我们使用图块将输入帧划分为更小的块,并检测每个图块中的对象,而不会因调整大小而牺牲信息。这些图块由蓝色矩形标识,我们利用在VisDrone数据集上训练的预训练SSD-MobileNet-v1模型。
