Mind the System Gap: System-Level Implications for High-Performance Edge AI Coprocessors

Intro
The new generation of domain-specific AI computing architectures is booming. The need for these and the benefit they provide to end applications are apparent. However, the inherent challenges in their development and development with them may not be. Specifically, the out-of-the-box interoperability and ease-of-use of decades-old architectures is the expected user and developer experience, but it does not go without saying when you build a new high performance processor from scratch, especially one with a novel architecture.
These are validation and system challenges. The AI processor needs to deliver the best performance within a system’s constraints and without burdening its resources. It needs to integrate into common ecosystems. A novel architecture amplifies this inherent challenge because there is little existing legacy to rely on. Entering a new architectural domain requires new hardware and compatible software to be designed (you can read more about it in our domain-specific architectures post). You need to devise your own system benchmarking and validation processes and you will not have common-use feedback on their results.
It is very common to evaluate an AI chip’s performance based on common industry benchmarks using parameters such as latency, throughput (frames or inferences per second) and power consumption. However, vendor-provided numbers need to be taken with a grain-of-salt. Measurements are done in laboratory conditions and neglect the effect the entire system will have on the accelerator’s performance and efficiency inside real-world edge devices.
System validation of an AI accelerator is taking the evaluation beyond sterile lab conditions. The System Validation team’s job is to make sure that the chip functions in various system environments and customer ecosystems, as well as to align expectations about performance, product fit and the required integration and development efforts. This is done by simulating as many combinations as possible of use conditions, environments, and tasks.
Here are some of the major components and considerations that go into making this happen.
Software stack
An AI accelerator is required to work with a complicated matrix of compatibilities and integrations on all software levels. The components of this matrix are:
- Architectures: x86, various ARM architectures (32-bit, 64-bit)
- OS and build environments: Android, Ubuntu, Windows, Yocto, etc.
- Software stack and driver support across multiple system and software configurations, e.g. Linux Kernel, GCC version, Python version, open-source library dependencies and more
- Efficient software frameworks and data pipelines for sending and receiving data from the accelerator: GStreamer, Open-CV and others
These can come in varied combinations in customers’ ecosystems. Any gap in this matrix that is not pre-validated can cause accelerator and system performance degradation or even install failure. Accounting for all possible variations requires running hundreds of thousands of tests on a vast number of different platforms and configurations to monitor closely the results and variations between each one. For example, a common configuration that needs special provisions in the PCIe driver is the DMA address space of the platform – 32- or 64-bit. For the chip to be able to work smoothly in both 32- and 64-bit systems and achieve high performance, the PCIe driver should “talk” in 32-bit DMA commands.
In addition to covering this vast matrix of configurations, we need to validate and benchmark each configuration with common APIs, programming languages, data stream pipelines and more. For example, if will take the Gstreamer as the data pipeline, do not optimize running the send and receive to and from the AI accelerator and keep some of the vision tasks running on the CPU (and not on the accelerator; tasks such as crop, scale, format conversion and so on), the runtime software will impact all major application KPIs, including performance, latency and CPU and memory utilization. This degradation will be caused by the data stream interconnect, not the runtime itself – we will probably see no degradation if we run the runtime by itself.
In edge environments, there are also deployment and upgrade mechanisms an accelerator runtime software needs to account for. These include things like remote or no internet access edge devices, limited disk space and/or host capacity and others. These are common and provisioning for them is crucial for an accelerator to truly be an edge AI accelerator.
System Bandwidth
The edge deployment environment has many system-level constraints that can limit bandwidth and thus AI accelerator and the entire system performance.
To take one prominent example, let us look at the connection interface, which is usually the first system decision when planning to integrate an AI accelerator. There are many interface options, including PCIe, Ethernet, MIPI etc., each with multiple different configurations. To take the PCIe as an example, there are multiple sets of configurations that can drastically impact system performance. The PCIe has connectors with different numbers of lanes. The varying bandwidth and current budgets can cap performance through limiting data transfer rates to and from the chip and/or chip power consumption. For instance, an M.2 bay used for connectivity has x2 lower bandwidth than an M.2 bay used for nVME. The PCIe protocol version is another important attribute that can impact the data transfer performance (e.g. Gen 3, has x3 bandwidth compared to Gen 1).
Calculating system performance expectations is critical when running system tests/benchmarks on multiple systems. To illustrate, if we would like to benchmark a neural network processing multiple full-HD resolution video in real time on our AI accelerator, the PCIe data transfer performance should be:

This rough calculation shows that using a Gen 3 1-lane PCIe interface that can reach a ~1GB per second transfer rate will essentially cap the AI accelerator’s high throughput. As a result, performance will drop to about 20 FPS. Such degradation can be detrimental to the end application and therefore important to consider in advance.
This is a simplified calculation for a case where the data travelling back and forth through the interface consists of the input and output of the neural network alone. With some AI accelerators this traffic also includes intermediate calculations being sent to the RAM and retrieved from it. This, of course, will put an even greater strain on the interface and will require an additional provision of bandwidth, memory and system power or result in even greater degradation in performance and power efficiency. Depending on model and input resolution, it could go as far as the accelerator not being able to handle the task at all.
Another example is memory. RAM capacity is usually very strict and if you reach it, the system will swap and allocate the memory it requires to a slower disk, like a hard disk. This is a penalty in terms of processing speed and will affect general system performance.
From a validation standpoint, any system test or benchmark should confirm the system memory and system bandwidth KPIs and make sure to monitor that RAM usage and interface bandwidth are at the expected level.
CPU utilization
Integrating an AI coprocessor (or in the case of an AI engine inside a heterogenous SoC), we need to be mindful of CPU utilization. Any application will need to run on the AI accelerator and on the general-purpose processor and, ideally, the former should not overburden the latter. The general-purpose processor should not take on any part of the neural workload. It should send and receive the data (NN input and output) and run the non-neural parts of the application (like reading from the sensor and database). In addition to its neural responsibilities, an accelerator may even have the ability to offload tasks from the CPU (like the NMS post processing, for instance), freeing up CPU capacity for other things.
We want our CPU-AI accelerator pair to perform on the neural task as close to the standalone AI accelerator as possible. It should not matter if you are using a weaker or more powerful CPU, you should get roughly the same performance.
In our validation practices, we do not only monitor CPU utilization, but we also run tests and benchmarks that examine the accelerator in real-world end-to-end embedded applications. In some tests, we intentionally over-utilize the CPU to make sure that neural performance is not affected.
Mechanical and Environmental Conditions
Edge AI devices are operating in a wide range of conditions that can affect AI and system performance dramatically or impact AI accelerator integration into the system.
It is important to make sure the accelerator is compliant with the system’s power and thermal constraints, as edge and embedded systems often have a limited power source and TDPs (Thermal Design Power). It is crucial to also consider the power efficiency and thermal level of the accelerator in various workloads (to learn more about power considerations and power efficiency in AI, read our blog). We want to make sure that the chip operates at a range of power consumption points for a given thermal solution. In other words, we would like to make sure our customers can run and provision their system for the workload they need, be it a power-hungry workload or a small, economical one.
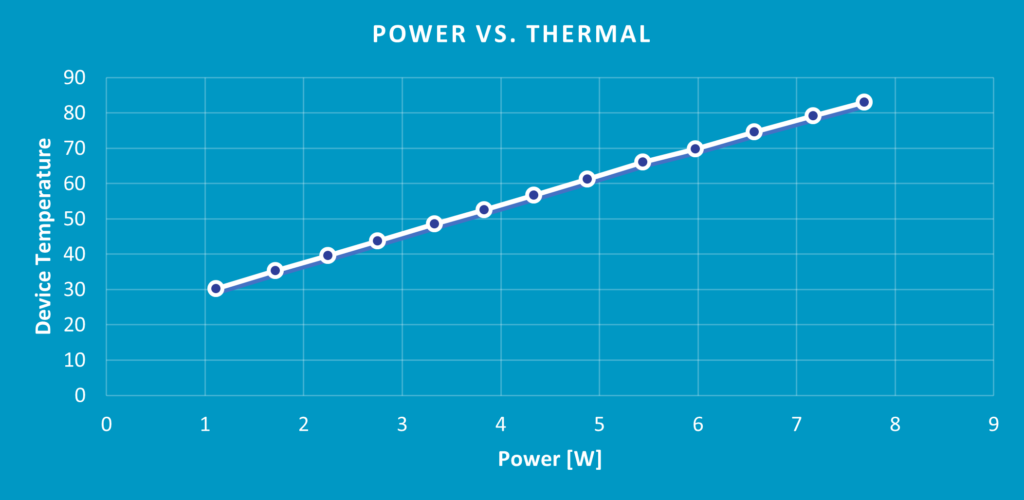
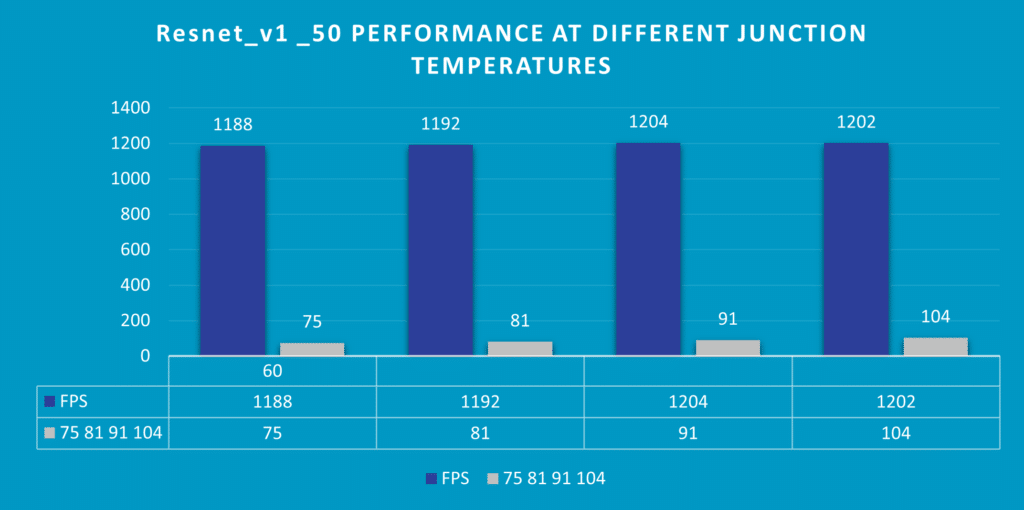
Also, the junction temperature (idle system temperature = room temperature) on the edge can be very high due to space or power constraints. As this can affect AI accelerator power and performance, a good system validation process needs to simulate real-world environments, including. different junction temperatures, and make sure the benchmarks and KPI are met.
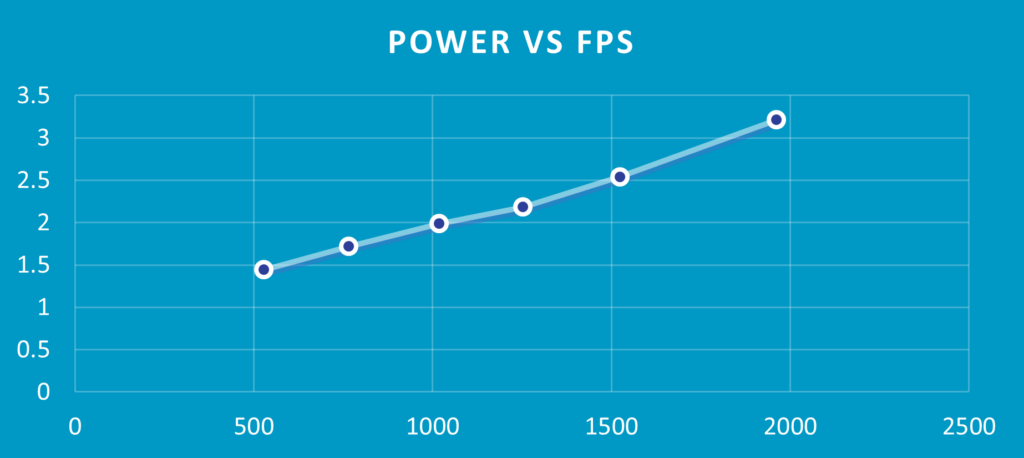
Moreover, the chip should have the capability to change power states to adapt to the system’s environment, performance requirements (by the specific task or application) and power demands (to save power, to cool the device etc). Power states can be PCIe interface power states or different power modes (like high performance, power saver etc.). In the transition between the different power states, the AI accelerator needs to adjust seamlessly and maintain or adjust performance. This needs to happen in a predictable way, which requires dedicated meticulous system testing.
Conclusion
An AI accelerator should operate smoothly and consistently within any ecosystem and software stack configuration. This is what is implied by the term maturity. Having a working chip is not enough – robust and mature software is crucial for its real-world usability for developers.
The Hailo System Validation team’s mission is to translate the industry-leading performance and power efficiency of our chip to the real world. This what paves the way to a volume-production product that works in a wide range of systems.
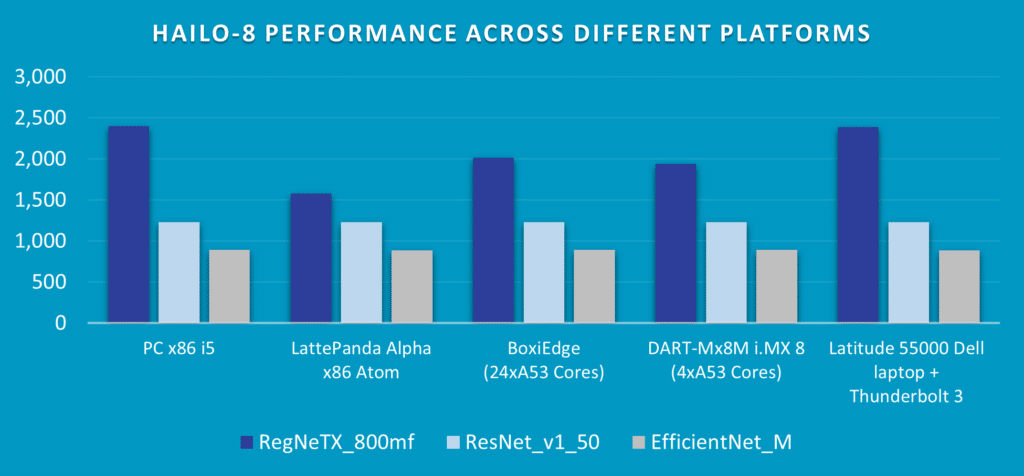
For more information about the Hailo-8 AI processor, check out our AI benchmarks!