Unlocking Edge AI: A Lot of Compute Goes a Long Way

Recently, Hailo unveiled its new M.2 module and published some exciting benchmarks. Looking at the impressive numbers, one naturally asks: “why would anyone need an object detector running at 1000fps?”
At first glance, the answer is simple – it is just an AI benchmark. An apples-to-apples comparison that gives you a rough estimate of the deep learning compute capabilities of competing solutions. But then, of course, one would immediately ask: “why would anyone need so much edge AI compute?” The answer usually given here is a straight-forward “more is better”.
What I want to argue here is that “more is different”[1] – at the product level, having an abundance of compute means that R&D efforts are spent on qualitatively different problems. Free from the tyranny of compute optimizations, a developer can focus her efforts on application and product, fostering new ideas and improving time-to-market. But to make that point, we are going to have to see what we can actually do with an object detector running at 1000fps.
Trading Framerate for Pixel-Rate
Data-center workloads exploit high throughput by setting up inference servers that aggregate requests from many endpoints. For edge systems, the corresponding workload is aggregating data from many video streams. Indeed, one efficient use of high-throughput object detectors is to process streams from many cameras. An object detector running at 1000fps can process 33 concurrent low-resolution streams in real time. However, we do not have to assume that the streams come from different sources. In fact, they can all be from the same high-resolution stream!
Object detectors naturally benefit from working at higher resolutions. As resolution increases, smaller objects have more pixels, making them easier to detect, even with simple network architectures [2]. We should clarify that by “small objects” we mean objects that span a small area of the image. For instance, if you mount a standard smartphone camera on a pole at a height of about 50 meters above a highway (see Figure 2), a car will occupy about 0.01-0.05% of the pixels in the camera’s sensor. If you are working with a network whose input resolution is 300×300, a car would, on average, occupy only 1-5 pixels, making it near impossible to detect. At Full-HD (1920×1080), the same car would instead occupy 40-200 pixels which is usually enough for successful detection. Thus, a system able to process higher resolutions can detect objects of interest from further away. For smart cities that means fewer cameras are needed to analyze a given area.
Now, say you are working on a smart city traffic management system. All you have at your disposal is a 300×300 object detector running at 1000fps, but what you would really like is an object detector running at FHD at 30fps. What you can do is treat the FHD image as a macro-frame composed of roughly 28 smaller 300×300 frames. To handle a rate of 30 macro-frames per second we need to be able to process ~850 300×300 frames per second (FPS), which, conveniently, is at our disposal. This idea of ‘tiling’ is illustrated in the following figure:
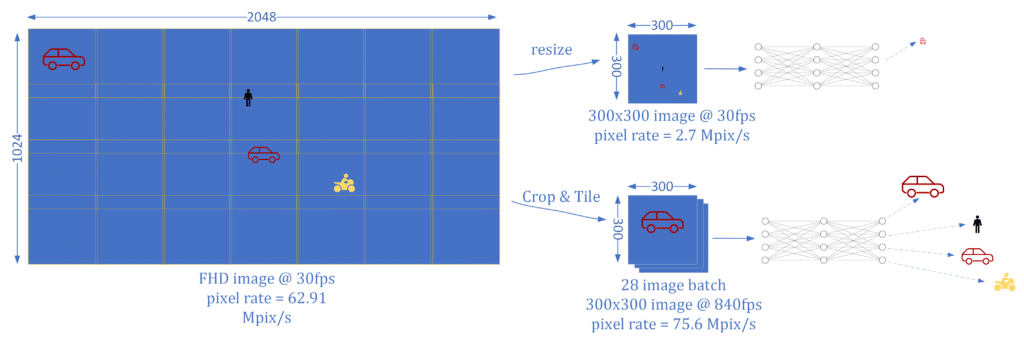
Looking at the figure above, the analogy between multi-stream and high-resolution processing is evident. Of course, we can mix and match to our heart’s delight. For instance, we can choose to process 4 streams at HD resolution (1280×720), where each HD frame is treated as a macro-frame composed of 7 300×300-sized tiles. The main idea is that our basic object detector running at very-high FPS affords us a budget of pixels-per-second which we can use as we see fit. From an accuracy standpoint, this solution is on par with having a model directly trained to process an FHD image, but it also offers many system-level advantages:
- We can switch resolutions “on the fly” without changing models. This can be used to implement a load-balancing mechanism where the application can choose a given trade-off between accuracy (resolution) and power (FPS). The working point can be data-driven based on the results of previous frames.
- We can implement something analogous to a zoom mechanism where we focus our processing power only on certain parts of the image. The patches that we want to process can be disjoint and the selection can be done frame-by-frame based on the results of previous frames.
- We can easily extend the system to work at different scales so that we can attend to both large and small objects.
Regardless, Hailo-8™ AI processor’s scalable dataflow architecture ensures that power consumption and throughput are solely a function of the amount of pixels-per-second being processed. So ultimately the developer can select between a model trained directly on FHD or a tiling approach based on her needs.
The important point is that when we have a high pixels-per-second budget to spend we can start saving on other things: neural network architecture compression and compute reduction, cloud-compute budget for training said networks, run-time optimization for deployment and much more. This is not just hyperbole. A while ago my group was tasked with creating a demo showing how Hailo-8™’s compute power can be leveraged to process high-resolution images. We had no propriety high-resolution data, no reference project (or pre-trained models) to draw inspiration from and, well, not a lot of time. What we did have was an off-the-shelf object detector and a chip with ample compute power. After a short literature survey we found an appropriate publicly-available dataset – Visdrone[3], and a reference that has already applied tiling to it [2]. All we had to do was retrain our object detection network on Visdrone and develop the application that handles the tiling. Two people working for several weeks were able to take it from an idea to a deployed demo, shown to customers, which can be seen in the figure below:

The Promised Land – Why Aren’t We There Yet?
The take-away message from the above exercise is not just about a conceptual framework for converting compute power into streams and resolution. There is a more subtle, but arguably more important, message: there is a discrepancy between the wealth of publicly available models, their ease of use and the scarcity of deployed edge solutions. This discrepancy is in large-part due to lack of compute.
One would be forgiven for having reservations. The above may be a nice anecdote, but a demo is not a product and not all problems are magically solved just because we have lots and lots of compute to throw at them. There are difficult problems that have nothing to do with compute in both data and algorithmic domains. I do not claim otherwise, but merely wish to contend that lack of compute prevents companies and users from focusing their efforts and energies on the right problems. Simply put, teams with access to low-power, high-compute platforms will be working on qualitatively different problems then their hamstrung peers.
In sum, I can do no better than quote Phil Anderson’s closing remarks in his seminal paper on how quantitative differences become qualitative ones:
“A dialogue in Paris in the 1920’s sums it up even more clearly:
Fitzgerald:The rich are different from us.
Hemingway: Yes, they have more money.”
Sources
[1] Anderson PW. More is different. Science. 1972;177(4047):393-396. i:10.1126/science.177.4047.393
[2] F. Ö. Ünel, B. O. Özkalayci and C. Çiğla, “The Power of Tiling for Small Object Detection,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 2019, pp. 582-591, doi: 10.1109/CVPRW.2019.00084.
[3] Zhu, Pengfei & Wen, Longyin & Du, Dawei & Bian, Xiao & Hu, Qinghua & Ling, Haibin. (2020). Vision Meets Drones: Past, Present and Future.