How Software Can Streamline Edge AI Developer Experience

When looking at the challenges facing mass AI adoption, infrastructure and integration are among their most important aspects. They were among the top limiting factors in a 2020 O’Rielly survey. The variety of frameworks, both for model generation and real-time deployment, also poses hurdles to ease and streamlining of development processes. In our experience, this is even more significant for successful edge AI adoption.
As described by others, the customer will have to collaborate closely with its vendor to overcome integration challenges and make sure that everyone has a clear understanding of the process. This requires the vendor to have broader expertise beyond his core competencies. For edge AI use cases, a customer may need to combine a dedicated inference accelerator (such as that of the Hailo-8) with a host processor. He or she would also need to port their neural net model to a format the accelerator can work with, which, in some cases, may require some modifications to the model to reduce its size. This is just one example of the tight collaboration required to make an edge AI project work, especially at scale.
Hailo has tackled and continues to tackle integration challenges on a regular basis. This has led us to pre-solve issues by developing several solutions and processes to simplify new customer onboarding and to support the problems existing customers may face when looking for an end-to-end edge AI solution.
One of the first key factors to successful onboarding we have identified is the ease of installation. Today, there is a plethora of existing approaches, starting from the old-fashioned installation manuals and all the way up to ready-to-go environments in the cloud. We decided to go with a simple approach of bundling our 4 core software packages into a single suite distribution available together in one Docker file. These include:
- Dataflow Compiler
- Hailo Runtime (Hailo RT)
- Model Zoo
- Hailo Applications (TAPPAS High-Performance Application Toolkit)
For those unfamiliar with Docker bundling, there is a variety of sources explaining its importance, ease of use and streamlining of Machine Learning (ML) development (2). In short, it allows the developer full control of the development environment with all the requirements for running the toolchain in one Linux container. For Hailo’s software suite users, it is as simple as pre-installing all our software tools and running the Docker container. We’ve seen that it simplifies our customers onboarding, working out-of-the-box with our core packages and running code examples smoothly and in a way they can be adapted to the customers’ use cases.
To provide examples for porting common state-of-the-art models, we created our own Model Zoo. This is common practice in the industry, but we have invested extensively in providing a wide range of examples covering many applications and included many common detection networks, ported from both PyTorch (via ONNX) and TF frameworks.

You can find out more about Hailo Model Zoo usage and the different models in this dedicated blog.
Another major challenge customers face with edge AI frameworks is the integration of third-party solutions into a real-time processing pipeline. Hailo has successfully leveraged the open-source streaming library GStreamer in support of our customers with pre- and post-processing operations that are not part of the neural core. The GStreamer is a common open-source library for building real-time computer vision pipelines that has become the de facto industry standard for such applications. For those unfamiliar with it, here is a good primer on GStreamer.
GStreamer allows our customers to build vision pipelines seamlessly, integrating the compiled NN model in the GStreamer processing flow.
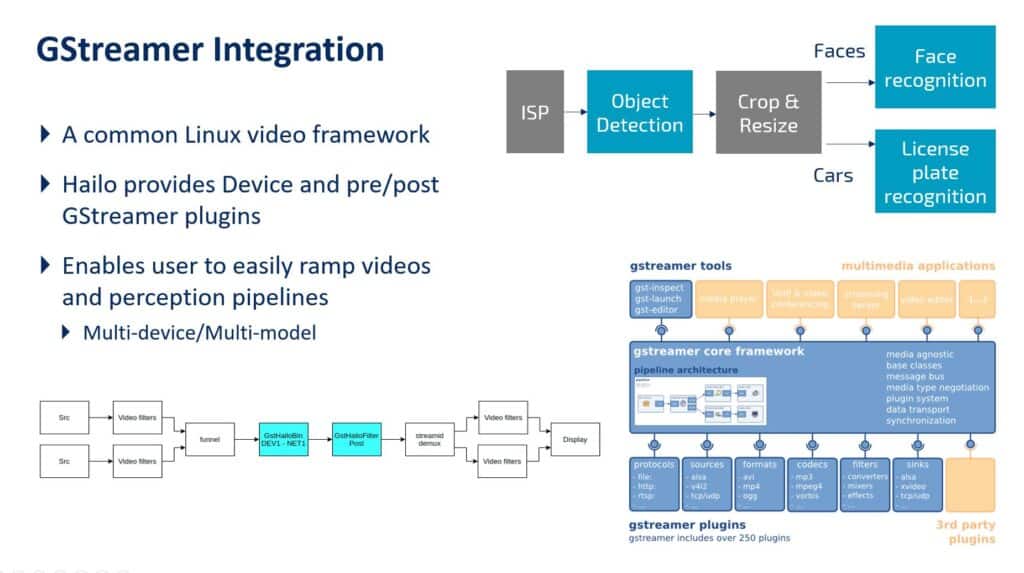
Furthermore, we created TAPPAS (Template APPlications and Solutions) – a rich bank of real-time deployment application examples, some of which are unique on the market. This package leverages both the HailoRT library and the GStreamer framework, demonstrating how Hailo’s compiled neural models can be integrated within common vision pipelines.

Example Development Flow Using Hailo’s Software Toolchain
Many Hailo customers’ vision projects are based on taking a computer vision model and deploying it into a real-time processing pipeline.
Figure 4 outlines the steps of the process of a common deep learning-based computer vision project developed using our toolchain.

Now let’s dive into a step-by-step build-to-real-time-deployment build flow that can be applied to any customer model.
A common starting point for a user would be to either take an off-the-shelf or proprietary model, in ONNX, CKPT, or SaveModel formats and take it through an iterative process of model conversion (also called model build) to optimize the inference-ready model for the Hailo hardware. A crucial step in the process is model optimization, which quantizes the model’s weights and activations to 4-16 bits, drastically reducing model size, as well as additional optimizations allowing the model to run faster in real-time, such as local (as opposed to global) image calculations. The model build process is usually done via the Dataflow Compiler’s API, guided by a step-by-step tutorial in Python notebooks. The output of this process is a compiled model file, ready for real-time deployment on Hailo hardware.
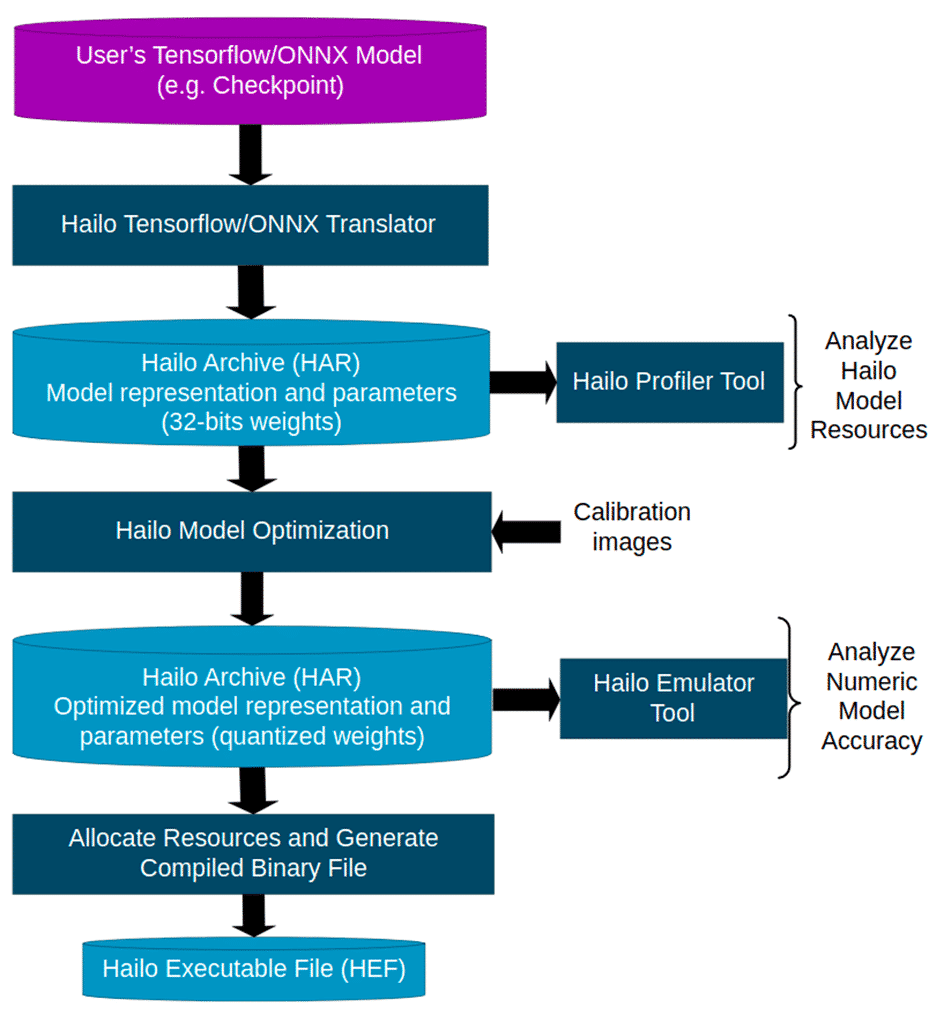
Next is integration of the compiled model into the customer’s vision pipeline. He or she would need to integrate the inference processing done on the Hailo-8 AI processor via the HailoRT library as part of their application. Usually, the non-neural processing is performed on the host processor (CPU), but Hailo’s software also supports offloading some pre- and post-processing operations onto a dedicated pre/post processing unit (PPU) on the chip itself. These include normalization, reshape, resize, YUV2RGB and some other common operations. The separation is done during the compilation in the model build stage and at run-time on the different chip components.
The real-time edge deployment environment can be drastically different from training, which is usually done on GPU-enabled servers. The former has significantly less compute capabilities and usually runs on a minimal Linux kernel such as Yocto. To ease the real-time application building process, we provide a rich library of real-time applications in the TAPPAS package, including various examples of common vision tasks using GStreamer as the vision pipeline and run on low-end real-time OS (such as Yocto).
Hailo strongly believes in leveraging the insights and knowledge gained from our five years of developing edge AI solutions to empower and support developers to achieve their goals. We has seen first hand what a difference such streamlining of development and deployment processes can make and are excited to see these enablers propel edge inferencing adoption forward, opening up many new opportunities for AI-enabled products.
Notes and Sources
- https://get.oreilly.com/ind_ai-adoption-in-the-enterprise-2020.html
- https://towardsdatascience.com/using-docker-for-deep-learning-projects-fa51d2c4f64c
https://aws.amazon.com/blogs/opensource/why-use-docker-containers-for-machine-learning-development/
https://analyticsindiamag.com/why-use-docker-in-machine-learning-we-explain-with-use-cases/
https://www.kdnuggets.com/2021/04/dockerize-any-machine-learning-application.html
https://www.analyticsvidhya.com/blog/2021/06/a-hands-on-guide-to-containerized-your-machine-learning-workflow-with-docker/