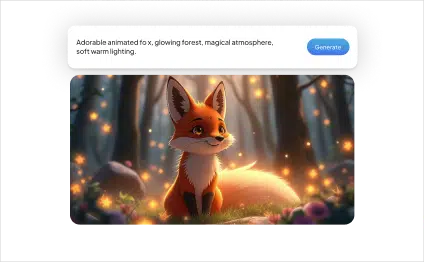
Generate multimodal responses by interpreting both text and images, enabling vision-language understanding and content creation
The pipeline processes image and text inputs using a vision
encoder and language model to generate contextualized outputs