エッジに生成 AI を導入:Hailo-10HのLLMの例

はじめに
エッジAIにおける大規模言語モデル(LLM)の実運用への適用は、リソース制約のある環境に先進的な人工知能機能をもたらすとして注目されています。本ホワイトペーパーでは、高性能かつ効率的なLLMのエッジデバイスへの実運用適用を可能にする先進AIアクセラレータ「Hailo-10H」について説明します。Hailo-10Hは、メモリ制約、省電力性、計算資源の制限といった独自の課題に対応しながら高い性能を実現します。革新的な最適化技術、包括的なツールチェーンのサポート、専用のランタイム環境を通じて、Hailo-10Hは開発者が性能や精度を犠牲にすることなく、多様なエッジアプリケーションにおいてLLMの力を活用できるようにします。
LLMとは?
大規模言語モデル(LLM)は、大量のデータセットからパターンを学習し、人間のようなテキストを処理・生成する高度なニューラルネットワークです。顧客対応チャットボット、自動コンテンツ生成、機械翻訳、コード生成など、商用領域で幅広く採用されており、産業全体にイノベーションをもたらしています。
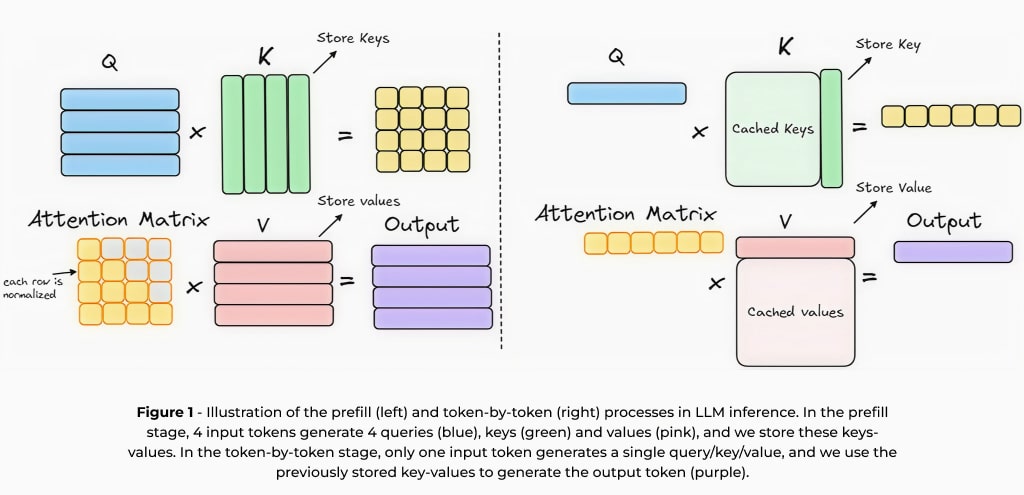
LLMは基本的に「自己回帰型アーキテクチャ」に基づいており、前の文脈に基づいて次の単語を逐次予測しながらテキストを生成します。この「次単語予測」の学習方法により、言語パターンを理解し一貫性のある応答を生成できます。ただし、この手法は新しいトークンを生成するたびに同じ文脈を繰り返し処理する必要があります。そのため推論を高速化するために、過去のトークンから得られた中間計算を保存して再利用する「キー・バリューキャッシュ(KV-cache)1」が一般的に用いられます。
LLM推論におけるKV-cacheは以下の2つのステージに分かれます:
- プリフィル(prefill)ステージ – 入力プロンプト全体を処理し、中間計算結果を生成して保存する段階。
- 生成ステージ – 保存されたキャッシュを利用し、逐次的に新しいトークンを効率的に生成する段階。
エッジデプロイ:利点と課題
現在は、クラウドベースのLLMが主流ですが、スマートフォン、車載機器、IoTデバイス、組込みシステムといったエッジデバイス上での実運用適用には以下の利点があります:
低レイテンシ/プライバシー保護/コスト削減/外部Network続性への依存度低減
これによりリアルタイムかつクラウドサーバーに依存せずコンテキストに応じた処理が可能になります。
一方で、エッジデバイスへのLLMの導入には以下のような特有な課題があります:
メモリ制約/計算効率/消費電力
前述の課題を解決するために、専用のハードウェアや、モデルの最適化技術が不可欠です。たとえば、15億パラメータのモデルに2KトークンのKV-cacheを用いる場合、4ビット重みでも約1.2GBのメモリを必要とします。
モデルのサイズが大きくなるにつれて、特にエッジデバイスでは、効率的なモデル実装のため、メモリ使用量の最適化が重要になります。モデルの重みの精度を低いビット表現に下げる量子化や、事前処理段階とトークンごとの生成段階の間での重みの共有などの手法は、パフォーマンスを維持しながらメモリの消費を最小限に抑えるのに役立ちます。このような最適化は、メモリ制約のあるエッジデバイスにLLMをデプロイする際、速度と精度を両立させるために不可欠です。メモリ要件のもう 1 つの重要な要素はコンテキスト長です。たとえば、Llama2-7Bで活性化に 8 ビット量子化を使用する場合、コンテキストの 1K トークンごとに、追加で 256 MB のメモリが必要となり、クラウドデプロイとは異なり、エッジ デバイスでは大きなコンテキスト長が制約となります。
性能指標と評価
LLM推論を評価する際の主要な指標は以下の2つです:
- TTFT(Time-to-First Token) – 入力プロンプトから最初のトークンが生成されるまでの待ち時間。リアルタイムアプリケーションでは極めて重要。
- TPS(Tokens-Per-Second) – 最初のトークン以降、トークンが生成される速度。会話型AIやストリーミング用途では滑らかさに直結。
TTFTの短縮は、音声アシスタントやチャットボットなどのリアルタイムアプリケーションにとって極めて重要であり、即時の応答はユーザーエクスペリエンスを向上させます。一方、TPSは、最初のトークンが生成された後に後続のトークンが生成される速度を意味しますので、モデルの流暢性と応答性に関係してきます。TPSが高いほど、よりスムーズで滑らかなテキスト生成が保証され、これは特に会話型AIやストリーミングアプリケーションに重要になってきます。
TTFTとTPSの両方を最適化することは、LLMのスムーズで効率的な動作を保証するためには必要不可欠です。
LLMが多様なユースケースにデプロイされる中で、モデルの精度を評価し、異なるモデルを比較することや、量子化の影響を評価することは、ますます複雑な課題となってきています。包括的な評価を行うためには、複数のデータセットと指標を使用するのが一般的です。たとえば、一般知識の質問応答、コード関連のタスク、要約の正確性などでモデルを評価することがあります。この課題は、ハードウェアの制約によりモデルサイズやコンテキスト長が制限されるエッジデバイス上で特に顕著になります。 次のセクションでは、モデルを効率的にファインチューニングし、特定のタスクに合わせて最適化するために作られた技術であるLow-Rank Adaptation(LoRA)について説明します。
LoRAとは?
LLM(大規模言語モデル)をゼロから学習させるには、多大な計算資源と専門的なインフラが必要となり、非常に高コストかつ時間のかかるプロセスです。そのため、事前学習済みのLLMを特定のユースケースに適応させる、より効率的な手法が一般的に用いられています。Low-Rank Adaptation(LoRA)は、その代表的な手法のひとつです。
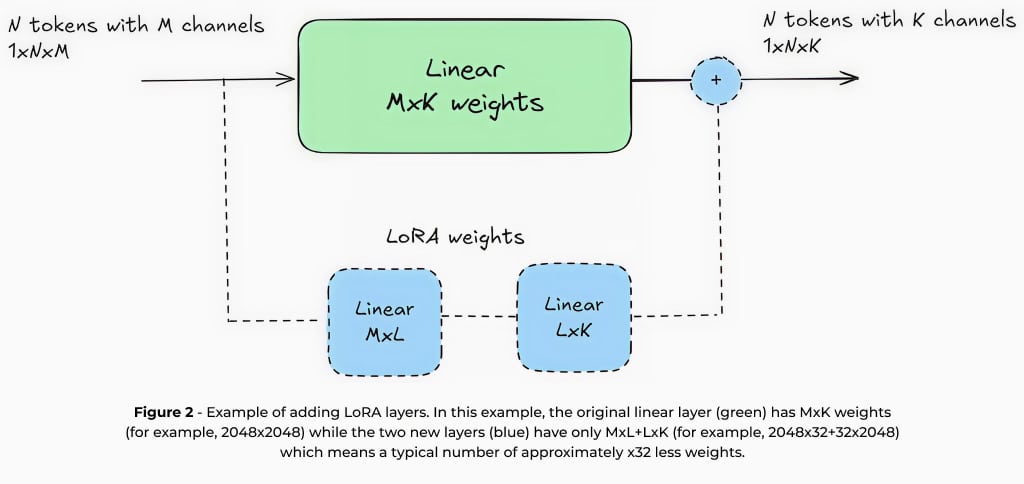
LoRAは、元のモデルの重みを固定したまま、パラメータ数が少ない(例:元のモデルの約1〜5%)小さな学習可能な層を追加することで機能します。LoRAでは更新されるパラメータがごく一部であるため、少量のデータセットと限られた計算資源でファインチューニングが可能です。たとえば、70億パラメータのLLMをLoRAでファインチューニングする場合、シングルGPUで実行できるため、計算機のハードウェアが限られている設計チームでも実用的なソリューションとなります。
さらに、LoRAでは数千件程度のデータセットで十分なため、特定領域への適応にかかるコストと労力を大幅に削減できます。
LoRAは学習効率だけでなく、エッジデバイスへの実運用適用においても大きな利点があります。モデルの大部分の重みが変更されないため、複数のLoRAアダプターをメモリ制約のあるデバイス上で動的に保存・切り替えることが可能です。これにより、単一のベースモデルで複数のタスクを効率的に処理できます。たとえば、スマートカメラでは、画像キャプション生成、OCR、ナンバープレート認識などに、それぞれ別のLoRAアダプターを備えた単一のモデルを使うことができます。また、特定のタスクにモデルをファインチューニングすることで、より小さなモデルでも高い精度を達成できるようになります。これは、汎用目的で設計された大規模なクラウドベースモデルとは異なります。たとえば、要約タスクに特化してファインチューニングされた15億パラメータのモデルは、汎用の70億パラメータモデルよりも高い精度を発揮することがあります。
これらの利点により、LoRAはエッジデバイス上でLLMを実運用適用するための重要な技術となっており、限られたリソースと高品質なAI性能のギャップを埋める役割を果たしています。
Hailoでは、LLMのエッジデバイスへのデプロイにおいて最高のAI体験を提供するため、ツールチェーン全体に包括的なLoRAサポートを統合しています。これにより、開発者は特定のユースケースに合わせてLLMモデルを効率的にカスタマイズし、エッジ環境の電力・メモリ制約の中でも最適な性能を維持することが可能になります。
Hailo-10HでのLLMの実行
Hailo-10Hは、エッジデバイス上で効率的に生成AI(GenAI)の推論を行うために設計された高度なAIアクセラレータであり、最小限の消費電力で高いパフォーマンスを発揮します。このハードウェアは、Hailo独自のニューラルコアと、アクセラレータ専用のDRAMを接続できるDRAMコントローラーを備えています。本稿では主に大規模言語モデル(LLM)に焦点を当てていますが、Hailo-10Hは、Vision Language Models(VLM)や画像生成、従来型の画像認識モデルなど、LLM以外にも多くのモデルを高い性能で実行できる能力を持っています。
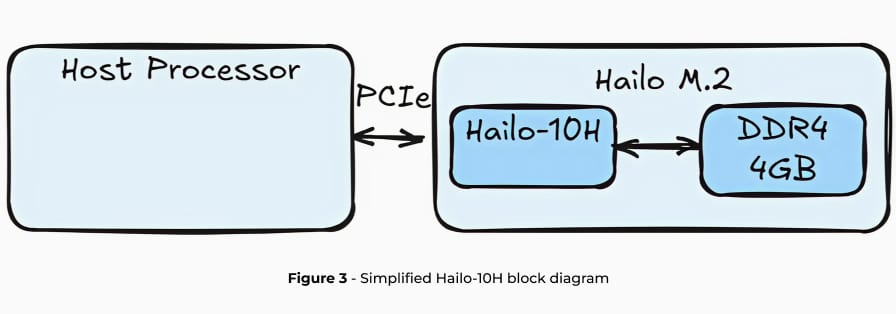
Hailo-10HでLLM(大規模言語モデル)を実行する際には、LLMの全パイプラインがアクセラレータにオフロードされ、ホストプロセッサの使用率やDRAM容量への影響を最小限に抑えます。次の2つのセクションでは、LoRA(Low-Rank Adaptation)対応、モデルの最適化、Hailo Dataflow Compiler(DFC)によるコンパイルを含む、LLMデプロイのためのHailoの完全なツールチェーンについて説明します。また、HailoRTを通じてHailo-10Hエッジデバイス上で簡単に動作できるよう、ランタイムライブラリやAPIも提供されています。
QWEN2-1.5B-Instruct |
Hailo-10H |
TTFT |
289ms for 96 input tokens |
TPS |
9.45 |
KV-cache |
2048 tokens (~1536 words) |
Memory requirement |
1.2GB |
Weight quantization scheme |
Static, 4-bit symmetric, group-wise |
Activation quantization scheme |
Static, 8-bit asymmetric, per-tensor |
KV-cache quantization scheme |
Static, 8-bit asymmetric, per-tensor |
HellaSwag |
↑66.06 / 64.3 (full precision/quantized) |
C4 |
↓14.38 / 15.1 (full precision/quantized) |
WikiText2 |
↓10.08 / 10.5 (full precision/quantized) |
Average power |
2.1W |
Table 1 – Evaluation metrics describing LLM inference on the Hailo-10H AI accelerator
Dataflow CompilerのLLM
Hailo-10HでLLMを実行するプロセスは、標準的な言語モデルをエッジ向けに最適化された強力なモデルへと変換する、高性能な最適化エンジン「Dataflow Compiler(DFC)」から始まります。
Hailoは、2つの高度な量子化技術「QuaROT2」と「GPTQ3」を活用しており、これらはHailo Dataflow Compilerのモデル最適化ステージに統合されています。QuaROTは、重み行列にハダマード変換を適用することで、活性化における外れ値の特徴を緩和し、量子化全体の精度を向上させます。Hailoは、QuaROTを最適化時に実装しており、デプロイされたモデルに計算負荷を追加することはありません。
GPTQは、近似的な2次情報を用いてLLMの重みをマッピングすることで、ワンショットの事後学習量子化を可能にします。これらの技術は、業界標準となりつつあり、4ビットのグループ単位の重み圧縮や、8ビットの活性化量子化など、積極的な量子化を行いながらも高いモデル精度を維持することができます。
コンパイルプロセスは、事前に最適化された「Hailo Archive(HAR)」ファイルから始まります。これは単なるモデルではなく、包括的なデプロイパッケージです。このファイルには、プリフィルやトークン単位のモデル構成、キー・バリューキャッシュ構造、モデルの辞書やトークナイザーなど、重要なコンポーネントが含まれています。ユーザーは、デプロイされたワークフロー全体を簡素化する、完全に最適化された単一ファイルを受け取ることができます。
Low-Rank Adaptation(LoRA)は、プロセスにさらなる柔軟性を加えます。LoRAは任意ですが、特定のモデル層をターゲットにして性能を調整することが可能です。ツールチェーンは、LoRAアダプターの反復的な追加をサポートしており、各アダプターは個別に量子化されます。LoRAの重みは、HuggingFaceの豊富なオープンソースライブラリから取得することも、特定のユースケースに合わせてカスタム学習することも可能です。電子メールの要約からコード生成まで、開発者は多様なアプリケーションに向けてモデルをファインチューニングできます。 コンパイルの最終段階では、「Hailo Executable Format(HEF)」ファイルが生成されます。これは、Hailoデバイス上で推論を行うための最終的な成果物であり、HailoRTを使用して実行されます。HailoRTは、KVキャッシュの管理や後処理パラメータの設定など、LLM実運用適用を細かく制御できる包括的なAPIセットと共に提供されます

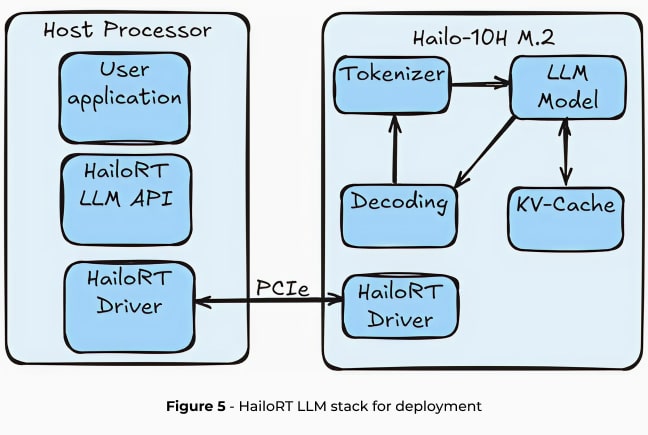
HailoRT Gen AI を使用した LLM のデプロイ
Hailo Runtime GenAI(HailoRT GenAI)は、Hailo-10H上でのLLM推論を簡素化する包括的なAPIスタックを提供します。シームレスな統合を目的として設計されており、HailoRTはLinux、Windows、Androidの各プラットフォームをサポートしています。ランタイムはLLMパイプライン全体を抽象化しており、トークン化から最終トークン生成まで、ホスト側のリソースを一切使用せずに処理を行います。
LLM推論パイプライン
HailoRT GenAIは、LLM処理を以下の4つの重要なステージに分割します:
- トークナイゼーション:入力されたテキストを埋め込みトークンに変換し、生のテキストをニューラルネットワーク処理に適した形式に整えます。このトークナイゼーション処理は、Hugging FaceのTokenizersパッケージを用いてRustで効率的に実装されています。
- モデル推論:次のトークンを予測するために、辞書全体にわたる確率ベクトルを生成するトランスフォーマーデコーダです。このモデルは、Hailoのニューラルネットワークコア上で推論されます。
- デコーディング:モデルが生成した確率ベクトルを解釈し、シーケンス内の次のトークンを生成します。
- KVキャッシュ:中間的な計算結果を保存することで、冗長な計算を排除し、推論速度を大幅に最適化します。
これらすべての処理はHailo-10Hにオフロードされるため、ホストプロセッサの負荷やモデルのメモリ使用量はごくわずかになります。このアプローチにより、CPU使用率やDRAM容量への影響を最小限に抑え、エッジAIの実運用適用を非常に軽量なものにしています。
柔軟な設定と制御
HailoRT GenAI は、拡張性のある設定インターフェースを通じて、LLM推論に対するきめ細かな制御を提供します。開発者は以下の項目を細かく調整できます:
- デコーディング手法:使用するデコーディング戦略の選択
- 温度設定(Temperature):モデルの出力のランダム性や創造性、予測性の度合いを制御
- Top-p(核サンプリング):確率の高いトークンの集合からサンプリング4
- 頻度ペナルティ(Frequency Penalties):既に出現したトークンの頻度に基づいて新しいトークンにペナルティを与える
- 最大トークン数の制限:生成されるトークン数の上限を設定
さらに、HailoRT は高度なコンテキスト管理機能も提供しています。ユーザーは以下の操作が可能です:
- LLMのコンテキストの保存、読み込み、クリア
- 異なる会話間の切り替え
- 会話の途中からの応答再開
- 単一のHEFファイル内で異なるLoRAアダプターをシームレスに切り替え
推論ワークフロー
推論ワークフロー
HailoRT 生成AI を使用して LLM を推論するには、次の 3 つの合理化された手順を実行します。
- 設定用API を使用して、HEF モデルを Hailo-10H の DRAM に転送します。
- 必要なメモリ リソースを割り当てて、ニューラル コアを構成します。
- 準備ができたら、入力プロンプトをモデルに送信し、出力の生成を開始します。
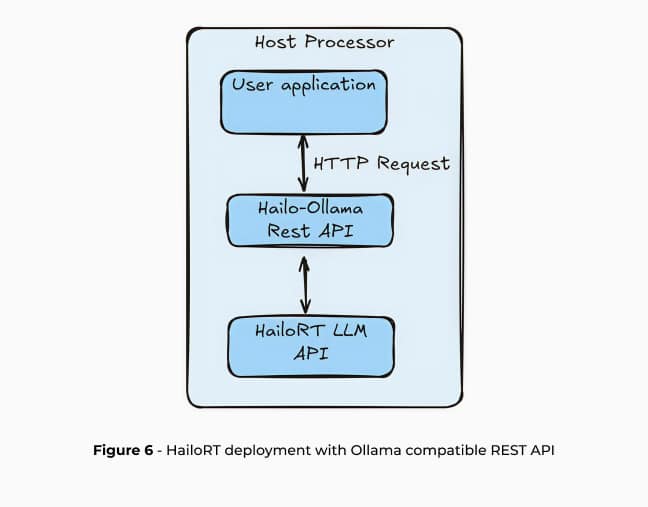
これらの手順は、HailoRT を介して直接 CPP API で使用することも、高レベルの REST API を介して使用することもできます。HailoRT 生成AI は、Ollama および OpenAI と互換性のある REST API を備えており、Hailo-10H 上でシームレスなアプリケーション開発を実現します。この統合は、複雑な AI インフラストラクチャと実際のエッジ AI 展開の間のギャップを埋めます。
Ollama5 は、LLMをローカルに展開するためのオープンソースプロジェクトで、LLMモデルの生成、実行、管理をシンプルなAPIで実現します。Open-WebUIとの統合によるユーザーフレンドリーなAIインターフェース、オープンソースのRAGエンジンであるRAGFlow、LLM評価を容易に実行できるOpenCompassなど、多様なアプリケーションに対応しています。Ollama は、OpenAI や Anthropic などの他のクラウドベースのソリューション API とも互換性があり、エッジ AI の展開への容易な移行を保証します。
まとめ
大規模言語モデル(LLM)はAIアプリケーションに革命をもたらしていますが、エッジデバイスへの実運用適用には、メモリ制約、計算効率、消費電力といった大きな課題が伴います。Hailo-10H AIアクセラレータは、Low-Rank Adaptation(LoRA)、高度な量子化技術(QuaROTおよびGPTQ)、そして包括的なランタイム環境(HailoRT)といった革新的な技術によって、これらの課題を解決します。
LLMのパイプライン全体を専用アクセラレータにオフロードすることで、Hailoはエッジデバイス上での効率的かつ低消費電力なLLM推論を実現。これにより、パーソナルコンピュータやスマートフォン、車載システム、IoTデバイス、組み込みシステムなどに高度なAI機能を最小限の計算負荷で導入することが可能になります。
将来に向けて、Hailoはこれらの機能をカメラ内蔵アプリケーション向けに設計されたHailo-15Hへと拡張する計画です。これにより、LLM、VLM(ビジョン・ランゲージ・モデル)、その他の生成AIモデルをカメラベースのシステムに直接組み込むことが可能になります。
Hailoプラットフォームは、さまざまなハードウェア構成に対応した堅牢なエッジAI実運用適用ソリューションを提供し、効率性、電力制約、柔軟性のバランスを実現します。さらに、LLM、音声認識(ASR)、画像生成(Stable Diffusion)、VLMなどを含む生成AIパイプラインにおいても幅広いサポートを提供しています。
- 詳細な解説動画は以下をご覧ください。:https://www.youtube.com/watch?v=80bIUggRJf4 ↩︎
- QuaROT:Quantization-aware Rotation Training:モデルを量子化(低ビット化)しても精度を落とさずに使えるようにする手法 ↩︎
- GPTQ:Generalized Post-Training Quantization:生成型事前学習トランスフォーマーのための高精度な事後学習量子化手法 ↩︎
- Top-pサンプリングの詳細:https://en.wikipedia.org/wiki/Top-p_sampling ↩︎
- 公式サイト: https://ollama.com/ ↩︎