Evaluating Edge AI Processor in the Generative AI Era

TOPS Matter, But They’re Not Enough.
As edge AI continues to revolutionize industries, choosing the right processor becomes a critical decision for developers and businesses. While the number of TOPS (tera operations per second) has historically been the go-to metric for evaluating AI hardware, relying on it exclusively can lead to oversimplified and misleading conclusions. Here, we’ll explore the nuances of comparing edge AI processors and what parameters should be factored.
Step 1: Balancing Compute and Memory
While TOPS provides a measure of raw compute capability, it tells only part of the story. To truly understand a processor’s performance, we need to consider the delicate balance between compute power and memory.
When does TOPS Matter?
The architecture of the neural networks selected for each application, defines the amount of compute power. As the required compute power is linear with input size, the necessary compute for video or image processing, which is defined by the number of pixels multiplied by the number of frames per second (FPS), is higher than the compute power required to process time series input (like audio or radar) which is defined by the sampling rate. Since language is a highly condensed and abstract form of communication, it allows vast amounts of meaning to be transferred using far less data than the dense, high-dimensional inputs of images or video, therefore requiring significantly less compute to process.
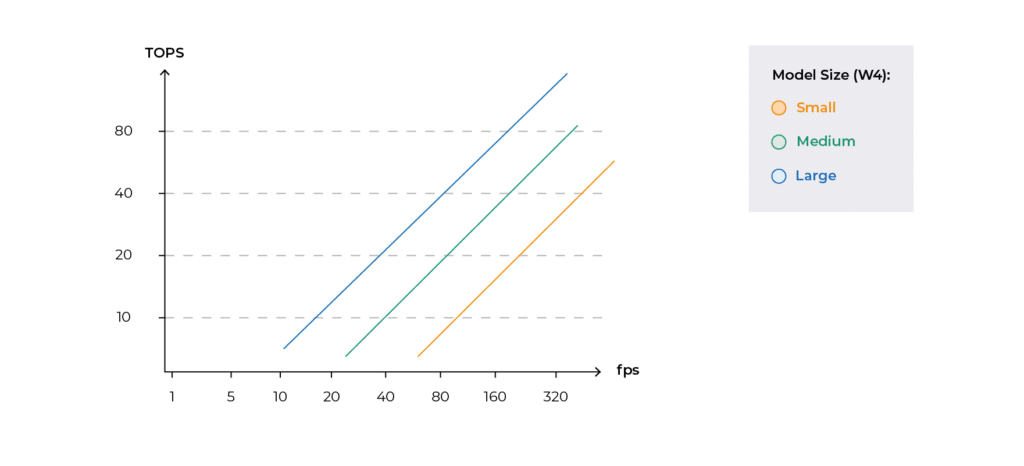
As can be seen in the graph in Figure 1, the compute resources required are linear to the model size and the input throughput.
The compute resources needed per input sample varies by orders of magnitude across different AI tasks.
- Perceptive AI (e.g. object detection, classification): 100K operations per input sample, often processed at high frame rates and high resolutions
- Enhancive AI (e.g. low light denoising, auto-zoom, auto-focus): 10K operations per input sample
- Generative AI (e.g. LLM, VLM, text to image, etc.) – 1K operations per input sample
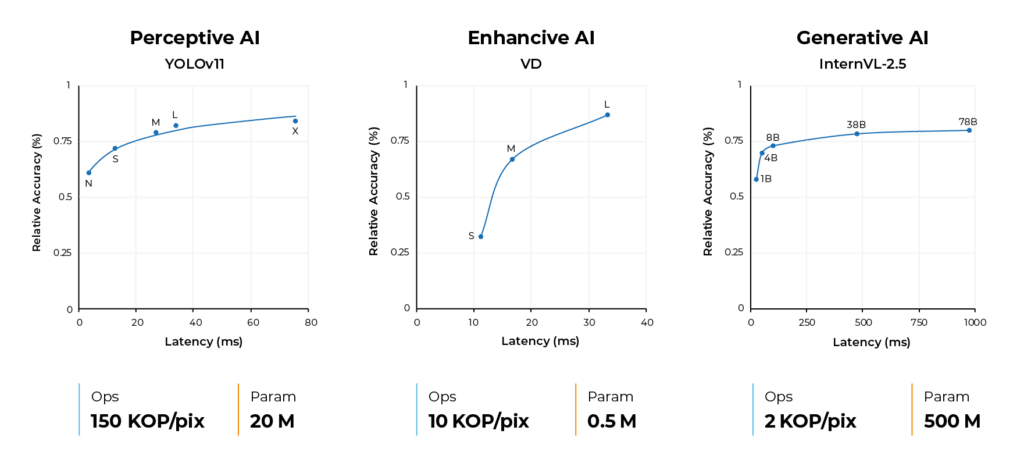
When does Memory Matter?
Perceptive and Enhancive AI models have a relatively low parameter count (<1M for enhancive and 10-100M for Perceptive). Processors with sufficient on-chip memory can handle such models without relying on off-chip memory, reducing latency and power consumption.
Generative AI models on the other hand, are in the scale of billions of parameters, with edge and mobile models ranging between 0.5B to 8B parameters. For such large models, off-chip memory (e.g., DRAM) becomes essential. With the orders-of-magnitude increase, the load on memory bandwidth per interface is growing beyond available bandwidth, and is dominating the system level performance. As can be seen in Figure 3, the Token-by-Token (TBT) performance does not scale linearly with model size. Doubling or quadrupling the model size doesn’t linearly double performance unless bandwidth also scales accordingly.
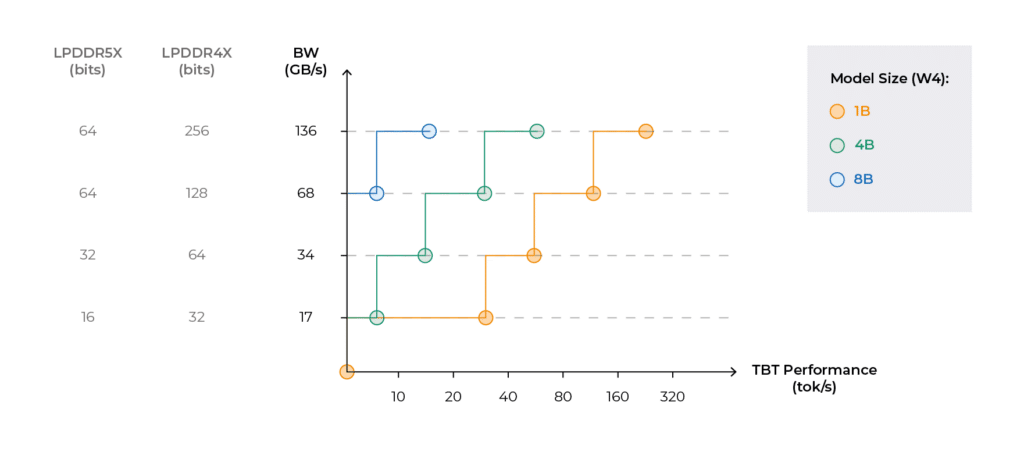
The bandwidth bottleneck is clear from this example. While a small language model with 1B parameters can reach a TBT performance of up to 40 tokens per second with 1 LPDDR4X memory with 17GB/s of bandwidth, a 4B model will requires quadrupling the memory bandwidth to reach the same performance.
Intermediate results are also a limiting factor. In architecture which performs layer-by-layer calculations (like GPUs) intermediate results also burden memory bandwidth, making the step points lower, or limiting the performance that can be achieved per memory resource.
In generative AI use cases, adding memory resources becomes critical to maintain high performance. However, this in turn introduces not only cost increase but also latency and higher power demands. Therefore a careful balance between all resources is required.
Balancing Compute and Memory Resources
For any AI application to run efficiently, a certain minimum of compute and memory is required. But beyond that threshold, the balance between TOPS and memory becomes workload-specific. Consider a high-resolution video analytics task. This workload demands significant compute power to handle large input frames and high frame rates while requiring moderate memory bandwidth to process those frames. Now contrast this with a natural language processing model, where the demands on memory far outweigh those on compute. When input is mostly text and/or audio, inference rate is at human interaction speed and thus memory bandwidth is the limiting factor, however, when video is involved this becomes more balanced as the image ingress processing phase is dominated by TOPS while the non-image modality is limited by memory bandwidth.
In each case, adding more TOPS or more memory without addressing the other will result in diminishing returns. For some applications, even with endless TOPS, the processor can’t perform because it hits a memory bottleneck. For others, ample memory won’t matter if there isn’t enough compute power to meet the task’s demands.
When picking an AI solution for edge application one practical approach is to guarantee barrier crossing within domain of operation. In practice, this means assessing the performance for each of the typical workloads at the desirable rate.
For instance, for an application of a security camera with a single video stream one would look for a processor that can handle >30 FPS of video enhancement, 10-15 FPS of perception task, and 1-2 FPS of VLM-based video analysis. This would dictate the balance in compute and memory resources, taking into consideration also power and cost envelopes.
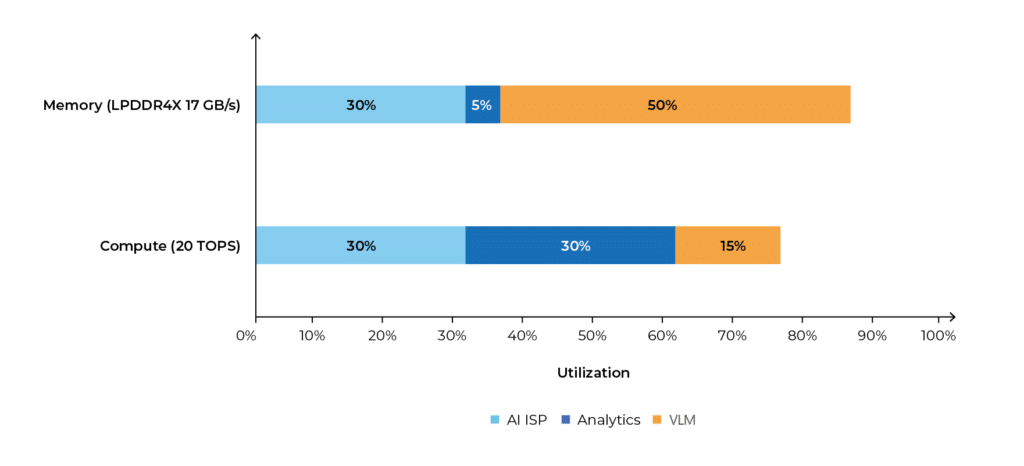
For example, in the Hailo-15 AI vision processor, which is equipped with a 32-bit LPDDR4X memory I/F and sports 20 TOPS, the ISP will consume ~30% of both memory and compute resources, while AI analytics will mainly consume compute resources, and applying a vision-language model (VLM) will be very demanding on the memory, and less so on the compute.
This dynamic interplay between TOPS and memory is critical to understanding why a single metric can’t capture a processor’s real-world performance. The optimal ratio between these resources varies not only across applications but also within specific working points of a single application.
Step 2: Understanding the Role of Use Case and Working Points
If balancing TOPS and memory forms the foundation of processor selection, the use case provides the blueprint for making informed decisions. Unlike cloud, where excessive load can translate into more instances for either compute or memory bandwidth, when it comes to edge there’s a power & cost envelope which needs to be settled through compromise between the various workloads to give a solution that is a good fit in actual deployment scenarios.
The requirements of a specific edge AI application dictate how compute and memory are prioritized and, more importantly, what trade-offs are acceptable.
Take power consumption, for example. In a compact IoT device, a tight power budget might force to prioritize energy efficiency over sheer performance. Meanwhile, an autonomous vehicle, with its substantial power reserves, will prioritize ultra-low latency and high reliability to ensure safe and real-time decision-making. Price is another consideration. A smart home assistant must stay within a competitive consumer price range, meaning its processor can only accommodate so much TOPS and memory before costs spiral out of reach. On the other hand, an industrial robot, where reliability and performance are paramount, can justify a higher investment.
Power, cost, and latency each introduce unique challenges when balancing compute and memory in edge AI systems.
Power: Compact devices like IoT sensors operate under tight power budgets, which necessitate energy-efficient designs. Processors that consume less power generate less heat, which is essential for compact edge devices without active cooling systems. Adding more compute or memory resources often increases power consumption, creating a delicate trade-off between performance and battery life. In contrast, systems like autonomous vehicles can afford higher power consumption to prioritize ultra-low latency and high reliability, ensuring safe and real-time decision-making.
Cost: Price constraints are another limiting factor. For consumer devices like smart home assistants, staying within a competitive price range restricts how much compute and memory can be integrated. Industrial applications, such as robotics, may justify higher costs for greater reliability and performance, but even here, budget imposes limits on the achievable balance, and designers are required to maximize compute performance and memory bandwidth within a restricted budget.
Latency: Different applications impose varying latency requirements. Automotive and industrial systems often demand instantaneous responses, as delays could have life-or-death consequences. On the other hand, retail analytics applications can tolerate higher latency as long as they maintain high throughput for tasks like customer behaviour analysis. These latency requirements also dictate the choice and distribution of compute and memory resources in a processor.
To choose the right AI accelerator, the journey begins by defining the working point—the intersection of budget, power, and latency constraints. Once these boundaries are set, the balance between compute power and memory can be evaluated, with the notion that both are limiting factors. Finally, the processor must be assessed against the specific requirements of the application. A solution designed for facial recognition in a smartphone will differ dramatically from one tailored for inspecting products on an assembly line.
A Final Note: Secondary Considerations for Edge AI Processors
Although the trade-off between TOPS, memory, and use case primarily drives the decision-making process, additional factors can also influence the final choice. A robust developer ecosystem, for instance, can simplify implementation and accelerate time to market. Similarly, the architectural flexibility of a processor – be it a CPU, GPU, or NPU – and its ability to adapt to a range of workloads may offer long-term value, especially when targeting diverse markets or applications.
Conclusion: A Holistic Approach
Selecting the best edge AI processor requires a nuanced understanding of how TOPS and memory interplay, tailored by the specific demands of the use case. Focusing solely on TOPS risks overlooking critical bottlenecks, just as ignoring application requirements can lead to suboptimal choices. By defining the working point, balancing compute and memory, and considering the broader application context, one can identify the processor that delivers the right combination of performance, efficiency, and cost-effectiveness.
Remember, the most powerful processor isn’t always the best – it’s the one that fits your needs perfectly.