










Bringing Generative AI to the Edge: LLM on Hailo-10H

Introduction
Edge AI deployment of Large Language Models (LLMs) represents the next frontier in bringing advanced artificial intelligence capabilities to resource-constrained environments. This whitepaper explores how Hailo-10H, an advanced AI accelerator, enables efficient LLM deployment at the edge, delivering high-performance while addressing the unique challenges of memory limitations, power efficiency, and computational constraints. Through innovative optimization techniques, including Low-Rank Adaptation (LoRA) of LLMs, comprehensive toolchain support, and specialized runtime environments, Hailo-10H empowers developers to harness the power of LLMs across diverse edge applications without compromising on performance or accuracy.
What is LLM?
Large Language Models (LLMs) are advanced neural networks that process and generate human-like text by learning patterns from massive datasets. They have been widely adopted in commercial settings for applications such as customer service chatbots, automated content creation, language translation, and even code generation, driving innovation across industries.
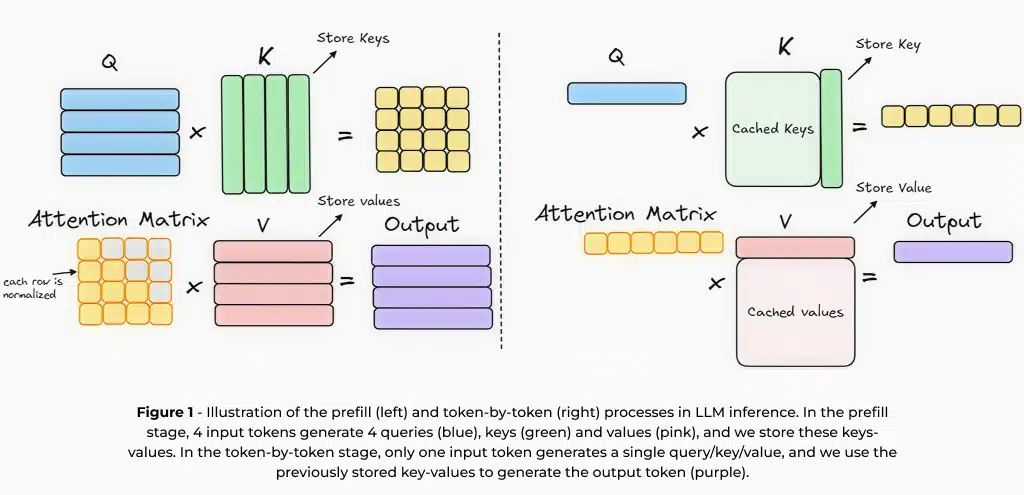
At their core, LLMs are built on auto-regressive architectures, which generate text sequentially, predicting each word based on preceding context. This next-word prediction training allows the model to learn language patterns and generate coherent responses. However, this method involves repeatedly processing the same context to generate new tokens. To accelerate inference, it is common to use a key-value (KV) cache1, which stores intermediate computations from previous tokens, reducing redundant processing and speeding up subsequent predictions. Inference using the KV-cache involves two key stages: (1) the prefill stage, where the input prompt is processed and intermediate computations are generated, and (2) the generation stage, which efficiently uses these cached results to generate tokens sequentially.
Edge Deployment: Benefits and Challenges
While cloud-based LLMs dominate most applications today, deploying them on edge devices – such as smartphones, vehicles, IoT devices, and embedded systems – provides multiple advantages. These include lower latency, improved privacy, lower cost, and enhanced resilience to connectivity issues, enabling real-time, context-aware processing without reliance on external servers. On the other hand, deploying LLM on an edge device also provides unique challenges related to memory constraints, computational efficiency, and power consumption that require specialized hardware and optimization techniques.
LLMs introduce significant challenges due to their large memory requirements. For example, a 1.5-billion-parameter model with a 2K token KV-cache requires approximately 1.2GB of memory when using 4-bit weights. As model sizes scale, optimizing memory usage becomes crucial for efficient deployment, especially on edge devices. Techniques such as quantization, which reduces the precision of model weights to lower bit representations, and weight sharing between the prefill and token-by-token generation stages help minimize memory consumption while maintaining performance. Such optimizations are crucial for deploying LLMs on memory-constrained edge devices while maintaining both speed and accuracy. Another important factor for memory requirement is the context length, for instance, each 1K tokens of context adds additional 256MB in Llama2-7B when using 8-bit quantization for activations which, unlike cloud deployment, also hinder large context lengths on edge devices.
Performance Metrics and Evaluation
To evaluate LLM inference performance two key metrics are commonly used: Time-to-First Token (TTFT) and Tokens-Per-Second (TPS). TTFT refers to the latency between submitting an input prompt and receiving the first generated token, heavily influenced by the prefill stage and computational efficiency. Reducing TTFT is crucial for real-time applications like voice assistants and chatbots, where immediate responses enhance user experience. TPS, on the other hand, measures how quickly subsequent tokens are generated after the first token appears, directly impacting the fluency and responsiveness of the model. A higher TPS ensures smoother and more fluid text generation, which is particularly beneficial for conversational AI and streaming applications. Optimizing both TTFT and TPS is essential for ensuring smooth and efficient LLM performance.
As LLMs are deployed across diverse use cases, evaluating their accuracy and comparing different models – or assessing the impact of quantization – becomes a complex task. To ensure a comprehensive evaluation, multiple datasets and metrics are typically used. For example, models may be tested on general knowledge question-answering, code-related tasks, and summarization accuracy. This challenge is even more pronounced on edge devices, where hardware constraints limit model size and context length. In the next section, we explore Low-Rank Adaptation (LoRA), a technique designed to fine-tune models efficiently and optimize them for a specific task.
What is LoRA?
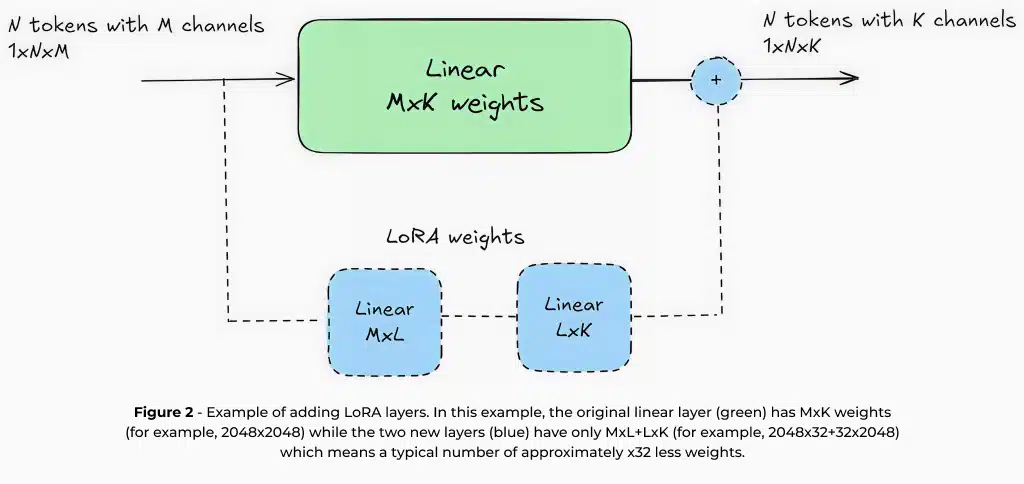
Training LLM from scratch is an expensive and time-consuming process, requiring significant computational resources and specialized infrastructure. For this reason, it is common to use more efficient techniques that adapt pre-trained LLMs to specific use cases while leveraging the knowledge already learned during their initial training. Low-Rank Adaptation (LoRA) is one of the most widely used methods for achieving this. LoRA works by adding small trainable layers with a limited number of parameters, e.g., approximately 1-5%, of the original model while keeping the core model weights frozen.
Since LoRA only updates a small subset of parameters, it enables fine-tuning with relatively little data and minimal computational resources. For example, fine-tuning a 7-billion-parameter LLM using LoRA can be performed on a single GPU, making it a practical solution even for organizations with limited hardware. Additionally, LoRA typically requires datasets containing only thousands of examples, significantly reducing the cost and effort needed for domain-specific adaptation.
In addition to its training efficiency, LoRA offers distinct advantages for edge deployment. Since most model weights remain unchanged, multiple LoRA adapters can be stored and swapped dynamically on memory-constrained devices. This enables a single base model to efficiently serve multiple tasks without excessive memory overhead. For example, a smart camera could use one base model with different LoRA adapters for image captioning, OCR, and license plate recognition. Second, fine-tuning a model for a specific task enables smaller models with lower computational requirements to achieve high accuracy – unlike large cloud-based models designed for general-purpose usage. For instance, a 1.5-billion-parameter model fine-tuned for summarization can outperform a 7-billion-parameter general-purpose model in its specific domain. These benefits make LoRA an essential technique for deploying LLMs on edge devices, helping bridge the gap between resource constraints and high-quality AI performance. In Hailo, we have integrated comprehensive LoRA support throughout our toolchain to offer a best-in-class edge AI experience for LLM deployment. This allows developers to efficiently customize models for specific use cases while maintaining optimal performance within the power and memory constraints of edge environments.
Running LLM on Hailo-10H
The Hailo-10H is an advanced AI accelerator designed for efficient GenAI inference on edge devices, delivering high performance with minimal power consumption. The hardware is based on Hailo’s unique neural core with a dedicated DRAM for the accelerator. Here, we focus on LLMs however, Hailo-10H is highly capable of running many more models beyond the scope of this paper such as VLMs (Vision Language Models), image generation, classical vision models and many more.
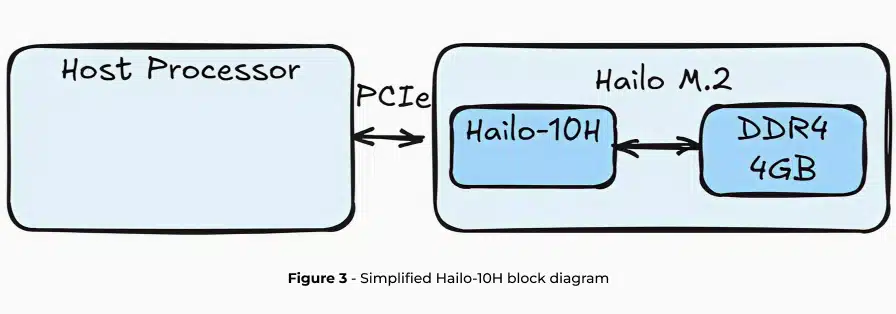
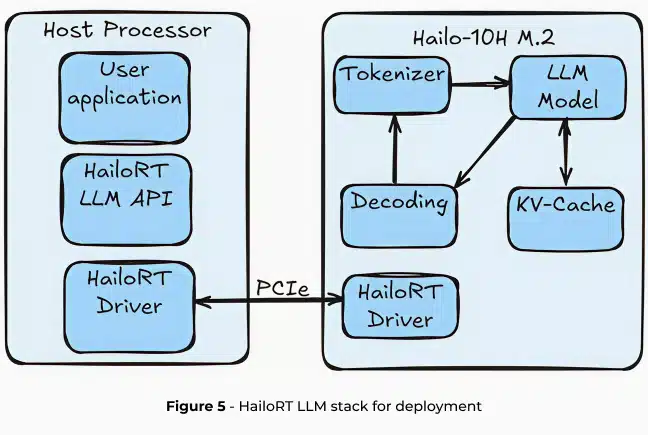
When running LLMs on the Hailo-10H, the entire LLM pipeline is offloaded to the accelerator while minimizing the impact on host processor utilization and DRAM capacity. In the next two sections, we will describe Hailo’s complete toolchain for LLM deployment, offering LoRA support, model optimization, and compilation using the Hailo Dataflow Compiler (DFC), along with runtime libraries and APIs for easy deployment on the Hailo-10H edge device through HailoRT.
QWEN2-1.5B-Instruct |
Hailo-10H |
TTFT |
289ms for 96 input tokens |
TPS |
9.45 |
KV-cache |
2048 tokens (~1536 words) |
Memory requirement |
1.2GB |
Weight quantization scheme |
Static, 4-bit symmetric, group-wise |
Activation quantization scheme |
Static, 8-bit asymmetric, per-tensor |
KV-cache quantization scheme |
Static, 8-bit asymmetric, per-tensor |
HellaSwag |
↑66.06 / 64.3 (full precision/quantized) |
C4 |
↓14.38 / 15.1 (full precision/quantized) |
WikiText2 |
↓10.08 / 10.5 (full precision/quantized) |
Average power |
2.1W |
Table 1 – Evaluation metrics describing LLM inference on the Hailo-10H AI accelerator
LLMs in Dataflow Compiler
The journey of running LLM on Hailo-10H begins with the Dataflow Compiler (DFC), a powerful optimization engine designed to transform standard language models into edge-ready powerhouses.
Hailo leverages two advanced quantization techniques: QuaROT2 and GPTQ3 that are fused to the Model Optimization stage of the Hailo Dataflow Compiler. QuaROT applies a Hadamard transformation to weight matrices, mitigating outlier features in activations and improving overall quantization. Hailo implements QuaROT during optimization without adding computational overhead to the deployed model. GPTQ complements this by enabling one-shot post-training quantization, mapping LLM weights using approximate second-order information. These techniques are de-facto becoming industry standards that allow for aggressive quantization – such as 4-bit group-wise weight compression and 8-bit for activations – while maintaining high model accuracy.
The compilation process starts with a pre-optimized Hailo Archive (HAR) file, which is more than just a model – it’s a comprehensive deployment package. This file encapsulates critical components including prefill and token-by-token model configurations, key-value cache structures, and the model’s dictionary and tokenizer. Users receive a single, fully optimized file that streamlines the entire deployment workflosw.
Low-Rank Adaptation (LoRA) adds another layer of flexibility to the process. While optional, LoRA allows users to adapt specific model layers for targeted performance. The toolchain supports iterative addition of LoRA adapters, with each adapter quantized independently. LoRA Weights can be sourced from HuggingFace’s extensive open-source library or custom-trained for specific use cases. From email summarization to code generation, developers can fine-tune models for diverse applications.
The compilation culminates in generating a Hailo Executable Format (HEF) file – the final artifact ready for inference on the Hailo device using HailoRT. HailoRT provides a comprehensive API set that enables fine-grained control over LLM deployment, including KV-cache handling and post-processing parameters.

Deploying LLMs with HailoRT GenAI
The Hailo Runtime GenAI (HailoRT GenAI) provides a comprehensive API stack that simplifies LLM inference on the Hailo-10H. Designed for seamless integration, HailoRT supports Linux, Windows and Android platforms. The runtime offers a complete abstraction of the LLM pipeline, handling everything from tokenization to final token generation with zero host utilization.
LLM Inference Pipeline
HailoRT GenAI breaks down LLM processing into four critical stages:
- Tokenization: Transforms input text into embedding tokens, preparing raw text for neural network processing. The tokenization process is efficiently implemented in Rust using the Hugging Face Tokenizers package.
- Model Inference: A transformer decoder that predicts the next token by generating a probability vector across the entire dictionary space. This model is inferred on Hailo’s neural network core.
- Decoding: Interprets the model’s probability vector to generate the next token in the sequence.
- Key-Value Caching: Stores intermediate computational results, dramatically optimizing inference speed by eliminating redundant calculations.
The entire pipeline is offloaded to the Hailo-10H, reducing host processor overhead and model memory usage to a negligible level. This approach ensures minimal impact on CPU utilization and DRAM capacity, making edge AI deployment truly lightweight.
Flexible Configuration and Control
HailoRT GenAI provides granular control over LLM inference through an extensive configuration interface. Developers can fine-tune:
- Decoding methods: select which decoding strategy would be used.
- Temperature settings: control the model’s output and determine whether it will be more random and creative or more predictable.
- Top-p: nucleus sampling4.
- Frequency penalties: penalize new tokens based on their existing frequency in the text.
- Maximum token limits: limit the number of generated tokens.
Additionally, HailoRT provides advanced context management. Users can:
- Save, load, and clear LLM contexts
- Switch between different conversations
- Resume chat responses from mid-conversation
- Seamlessly swap between different LoRA adapters within a single HEF file
Inference Workflow
Inferring an LLM with HailoRT GenAI involves three streamlined steps:
- Transfer the HEF model to the Hailo-10H’s DRAM using the configure API.
- Configure the neural core, allocating necessary memory resources.
- Once ready, send the input prompt to the model and begin generating output.
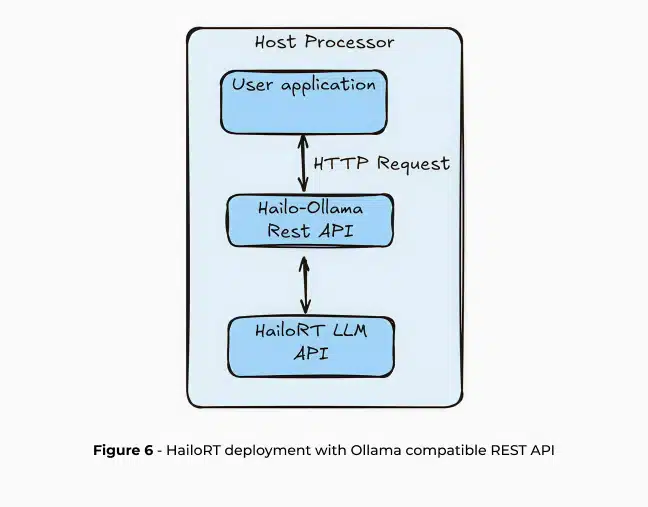
Those steps can be used with a CPP API directly through HailoRT or through a high-level REST API. HailoRT GenAI features a REST API compatible with Ollama and OpenAI, enabling seamless application development on the Hailo-10H. This integration bridges the gap between complex AI infrastructure and real-world edge AI deployment.
Ollama5 is an open-source project that allows deploying LLMs locally with a simple API for creating, running and managing LLM models for a variety of applications, including integration with Open-WebUI for user-friendly AI interface, RAGFlow, an open-source RAG engine and OpenCompass which allows you to easily run LLM evaluation. Ollama is also compatible with other cloud-based solution APIs such as OpenAI and Anthropic which ensures easy transition into edge AI deployment.
Summary
Large Language Models (LLMs) are revolutionizing AI applications, but their deployment on edge devices presents significant challenges related to memory constraints, computational efficiency, and power consumption. The Hailo-10H AI accelerator addresses these challenges through innovative techniques like Low-Rank Adaptation (LoRA), advanced quantization methods (QuaROT and GPTQ), and a comprehensive runtime environment (HailoRT). By offloading the entire LLM pipeline to a dedicated accelerator, Hailo enables efficient, low-power LLM inference on edge devices, offering developers a powerful solution for bringing advanced AI capabilities to personal computers and smartphones, vehicles, IoT devices, and embedded systems with minimal computational overhead. Looking ahead, Hailo’s roadmap includes extending these capabilities to Hailo-15H, designed specifically for in-camera applications, bringing LLM, VLM, and other generative AI models directly to camera-based systems. The Hailo platform offers a robust solution for edge AI deployment across a range of hardware configurations, balancing efficiency, power constraints, and flexibility with extensive support in GenAI pipelines including LLM, ASR, image generation (stable diffusion), VLM, and many more.
- Further explanation can be found in: https://www.youtube.com/watch?v=80bIUggRJf4 ↩︎
- QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs ↩︎
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers ↩︎
- Further explanation can be found in: https://en.wikipedia.org/wiki/Top-p_sampling ↩︎
- Official website: https://ollama.com/ ↩︎
Read mode about what we do
Hailo offers breakthrough AI accelerators and Vision processors

Blog
Scaling Up Video Management Systems
What is a video management system? Video Management Systems, also known as VMS, collect inputs from multiple cameras and other sensors, addressing all related aspects of video handling, such as storage, retrieval, analysis and display. VMS are typically used in the security and surveillance space, enhancing personal safety in public areas, office buildings, transportation terminals,…
Blog
Backing into the Future: Unlocking the Potential of Automated Parking
The technology advancements and market drivers that accelerate the transition to automated parking

Blog
Leveraging Vendor Partnerships for ADAS Success: LeddarTech and Hailo
It’s a late summer evening, you’ve had a long day at work and all you want to do is get home and relax, but the usual horrible traffic jam is worrying you. The thought of spending the next thirty minutes switching between the accelerator and brake pedals is frustrating. As per the INRIX 2022 report,…