将生成式人工智能引入边缘:Hailo-10H上的大型语言模型示例

导言
大型语言模型(LLM)的边缘人工智能部署是将先进人工智能功能引入资源受限环境的新前沿领域。本白皮书探讨Hailo-10H这一先进的人工智能加速器如何在边缘实现高效大型语言模型部署,在提供高性能的同时应对内存限制、能效和计算约束等独特挑战。通过创新的优化技术、全面的工具链支持和专门的运行环境,Hailo-10H让开发人员能够在各种边缘应用中利用大型语言模型的强大功能,而不降低性能或精度。
什么是大型语言模型?
大型语言模型(LLM)是先进的神经网络,通过从海量数据集中学习模式来处理和生成类人文本。它们已被广泛应用于客户服务聊天机器人、自动内容创建、语言翻译甚至代码生成等商业环境中,推动着各行各业的创新。
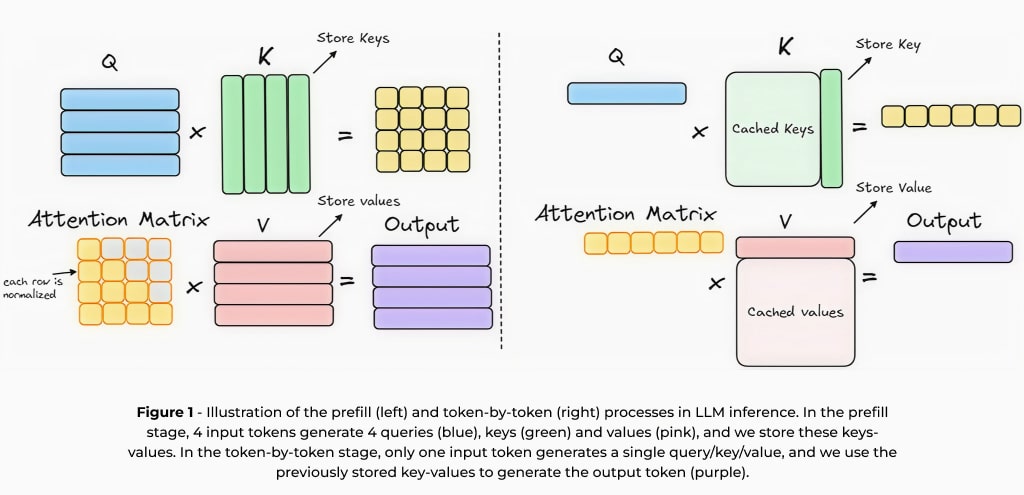
本质上,大型语言模型建立在自回归架构上,它按顺序生成文本,根据前面的上下文预测各个词语。这种后词预测训练可以让模型学习语言模式并生成有条理的响应。不过,这种方法需要反复处理相同的上下文来生成新词元。为加快推理速度,通常使用键值(KV)缓存1。键值缓存存储前一个词元的中间计算结果,从而减少冗余处理,加快后续预测速度。使用键值缓存进行推理涉及两个关键阶段:(1) 预填充阶段,在这一阶段处理输入提示并生成中间计算结果;(2) 生成阶段,高效利用这些缓存结果按顺序生成词元。
边缘部署:优势与挑战
虽然基于云的大型语言模型目前在大多数应用中占主导地位,但在边缘设备(如智能手机、汽车、物联网设备和嵌入式系统)上部署大型语言模型具有诸多优势。其中包括降低延迟、提高隐私性、降低成本以及增强对连接问题的适应能力,从而实现实时、上下文感知处理,而无需依赖外部服务器。另一方面,在边缘设备上部署大型语言模型面临着与内存限制、计算效率和功耗相关的独特挑战,需要专门的硬件和优化技术。
由于大型语言模型需要大量内存,因此产生了巨大的挑战。例如,在使用4位权重时,一个2K词元键值缓存的15亿参数模型大约需要1.2GB内存。随着模型规模的扩大,优化内存使用对于高效部署至关重要,尤其是在边缘设备上。量化等技术可将模型权重的精度降低到较低的位元表示,预填充和逐词元生成阶段之间的权重共享等技术有助于在保持性能的同时最大限度地减少内存消耗。这种优化对于在内存受限的边缘设备上部署大型语言模型同时保持速度和精度至关重要。内存需求的另一个重要因素是上下文长度,例如,在Llama2-7B中,当使用8位量化激活时,每1K词元的上下文会额外增加256MB,这与云部署不同,也会阻碍边缘设备上的大上下文长度。
性能指标和评估
为了评估大型语言模型的推理性能,通常使用两个关键指标:首词元时间(TTFT)和每秒词元数(TPS)。首词元时间是指从提交输入提示到收到第一个生成词元之间的延迟时间,这在很大程度上受到预填充阶段和计算效率的影响。降低首词元时间对语音助手和聊天机器人等实时应用至关重要,因为在这些应用中,即时响应可提升用户体验。每秒词元数则衡量第一个词元出现后后续词元生成的速度,直接影响模型的流畅性和响应速度。更高的每秒词元数可确保更流畅的文本生成,这对于对话式人工智能和流媒体应用尤其有利。优化首词元时间和每秒词元数对于确保大型语言模型性能平稳高效至关重要。
随着大型语言模型被部署到各种不同的用例中,评估其准确性以及比较不同的模型或评估量化的影响成为一项复杂的任务。为确保评估的全面性,通常会使用多个数据集和衡量标准。例如,可以对模型进行常识性问答、代码相关任务和摘要准确性测试。这一挑战在边缘设备上更为明显,因为硬件限制了模型大小和上下文长度。在下一节中,我们将探讨旨在对模型进行有效微调并针对特定任务优化模型的低秩适应(LoRA)技术。
什么是低秩适应?
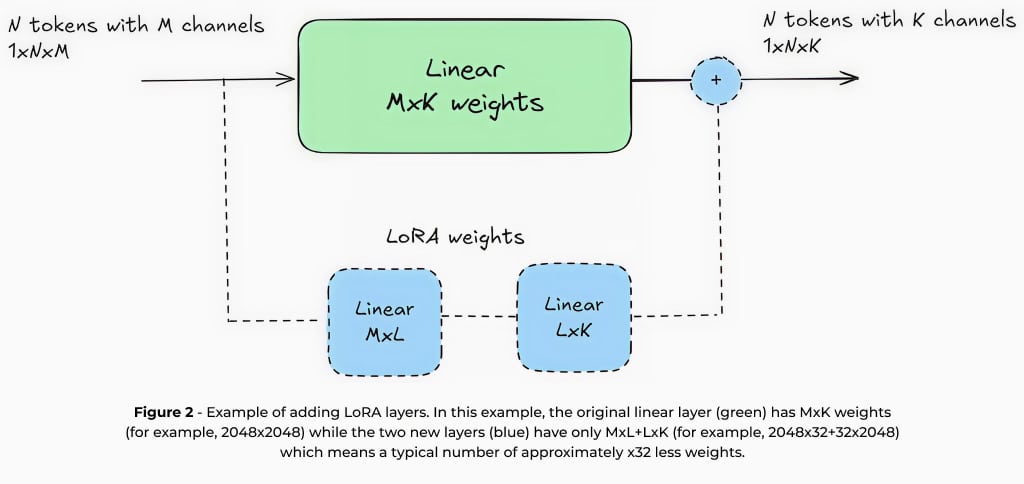
从头开始训练大型语言模型是一个昂贵而耗时的过程,需要大量的计算资源和专门的基础设施。因此,我们通常采用更有效的技术,使预先训练的大型语言模型适应特定的用例,同时利用在最初训练时已经学到的知识。低秩适应(LoRA)是为实现这一目标使用最广泛的方法之一。低秩适应的工作原理是,在保持核心模型权重不变的情况下,添加参数数量有限(例如约为原始模型的1-5%)的小型可训练层。
由于低秩适应只更新一小部分参数,因此只需相对较少的数据和最低限度的计算资源就能进行微调。例如,使用低秩适应微调一个70亿参数的大型语言模型,只需一个GPU即可完成,因此即使对于硬件有限的机构来说,这也是实用的解决方案。此外,低秩适应通常只需要包含数千个示例的数据集,从而大大降低了特定领域适应所需的成本和工作量。
除了训练效率之外,低秩适应还为边缘部署提供了独特的优势。由于大多数模型权重保持不变,因此可以在内存受限的设备上动态存储和交换多个低秩适应适配器。这样,单一基础模型就能有效地为多个任务提供服务,而不会产生过多的内存开销。例如,智能相机可以使用一个配备不同低秩适应适配器的基础模型,用于图像字幕、OCR和车牌识别。其次,针对特定任务对模型进行微调,可使计算要求较低的小型模型达到较高的精度,这与为通用用途设计的大型云端模型不同。例如,在特定领域中,一个针对摘要化进行微调的15亿参数模型可以胜过一个70亿参数的通用模型。这些优势使低秩适应成为在边缘设备上部署大型语言模型的基本技术,有助于缩小资源限制与高质量人工智能性能之间的差距。在Hailo,我们在工具链中集成了全面的低秩适应支持,为大型语言模型部署提供一流的边缘人工智能体验。这样,开发人员就能针对特定用例有效地定制模型,同时在边缘环境的功耗和内存限制下保持最佳性能。
在Hailo-10H上运行大型语言模型
Hailo-10H是一款为边缘设备高效生成式人工智能推理而设计的先进人工智能加速器,以最低的功耗提供高性能。硬件基于Hailo独特的神经内核,为加速器配备了专用DRAM。在这里,我们重点讨论大型语言模型,但Hailo-10H还能运行本文范围之外的更多模型,如VLM(视觉语言模型)、图像生成、经典视觉模型等。
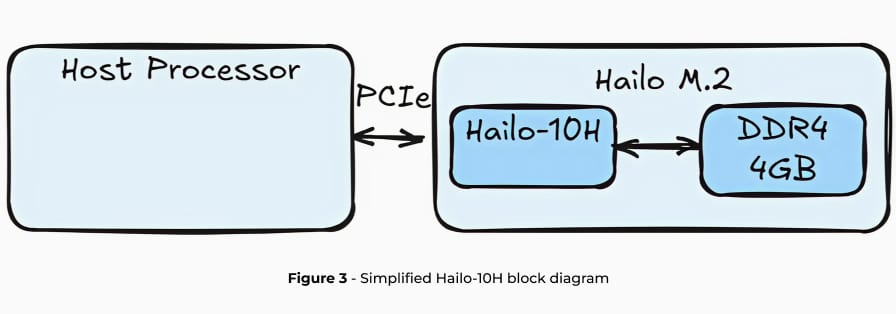
在Hailo-10H上运行大型语言模型时,整个大型语言模型管线都被卸载到加速器上,同时将对主机处理器利用率和DRAM容量的影响降至最低。在接下来的两节中,我们将介绍Hailo用于大型语言模型部署的完整工具链,包括低秩适应支持、模型优化以及使用Hailo数据流编译器(DFC)进行编译,并提供运行时库和API,以便通过HailoRT在Hailo-10H边缘设备上轻松部署。
QWEN2-1.5B-Instruct |
Hailo-10H |
TTFT |
289ms for 96 input tokens |
TPS |
9.45 |
KV-cache |
2048 tokens (~1536 words) |
Memory requirement |
1.2GB |
Weight quantization scheme |
Static, 4-bit symmetric, group-wise |
Activation quantization scheme |
Static, 8-bit asymmetric, per-tensor |
KV-cache quantization scheme |
Static, 8-bit asymmetric, per-tensor |
HellaSwag |
↑66.06 / 64.3 (full precision/quantized) |
C4 |
↓14.38 / 15.1 (full precision/quantized) |
WikiText2 |
↓10.08 / 10.5 (full precision/quantized) |
Average power |
2.1W |
Table 1 – Evaluation metrics describing LLM inference on the Hailo-10H AI accelerator
数据流编译器中的大型语言模型
在Hailo-10H上运行大型语言模型的过程始于数据流编译器(DFC),这是一个功能强大的优化引擎,旨在将标准语言模型转化为边缘就绪的引擎。
Hailo采用两种先进的量化技术:QuaROT2和GPTQ3,将其融合到Hailo数据流编译器的模型优化阶段。QuaROT对权重矩阵进行哈达玛变换,减少激活中的异常特征,提高整体量化效果。Hailo在优化过程中实施QuaROT,不会给部署的模型增加计算开销。GPTQ通过使用近似二阶信息对大型语言模型权重进行映射,从而实现一次性训练后量化。这些技术事实上已成为行业标准,可在保持高模型精度的同时进行积极的量化,如4位分组权重压缩和8位激活。
编译过程从一个预先优化的Hailo Archive(HAR)文件开始,它不仅仅是一个模型,还是一个全面的部署包。该文件封装了关键组件,包括预填充和逐词元模型配置、键值缓存结构以及模型的字典和词元生成器。用户收到一个经过全面优化的单一文件,可简化整个部署工作流程。
低秩适应(LoRA)为这一过程增加了另一层灵活性。虽然低秩适应是可选的,但它允许用户调整特定的模型层,以实现目标性能。工具链支持低秩适应适配器的迭代添加,每个适配器都可独立量化。低秩适应权重可从HuggingFace的广泛开源库获取,或针对特定用例进行自定义训练。从电子邮件摘要到代码生成,开发人员可以针对不同的应用对模型进行微调。
编译的最终结果是生成一个Hailo Executable Format(HEF)文件,这是最终成果,可在Hailo设备上使用HailoRT进行推理。HailoRT提供一套全面的API集,可对大型语言模型部署进行细粒度控制,包括键值缓存处理和后处理参数。

使用HailoRT GenAI部署大型语言模型
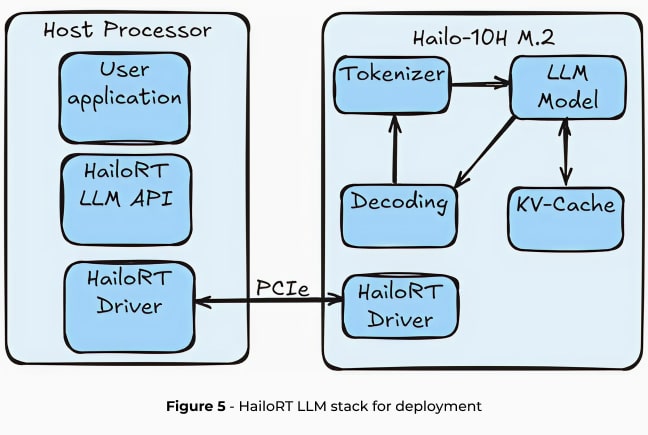
Hailo Runtime GenAI(HailoRT GenAI)提供一个全面的API栈,可简化Hailo-10H上的大型语言模型推理。HailoRT支持Linux、Windows和Android平台,旨在实现无缝集成。运行时提供大型语言模型管线的完整抽象,可处理从分词到最终词元生成的所有过程,主机利用率为零。
大型语言模型推理管线
HailoRT GenAI将大型语言模型处理分为四个关键阶段:
- 分词:将输入文本转换为嵌入词元,为神经网络处理准备原始文本。分词过程使用Hugging Face Tokenizers套件在Rust中高效执行。
- 模型推理:转换解码器通过生成整个词典空间的概率向量来预测下一个词元。该模型是在Hailo的神经网络核心上推断得出的。
- 解码:解释模型的概率向量,生成序列中的下一个词元。
- 键值缓存存储中间计算结果,通过消除冗余计算大幅优化推理速度。
整个管线被卸载到Hailo-10H,从而将主机处理器开销和模型内存使用量降低到可以忽略不计的水平。这种方法可确保对CPU利用率和DRAM容量的影响降到最低,使边缘人工智能部署真正实现轻量级。
灵活的配置和控制
HailoRT GenAI通过广泛的配置界面对大型语言模型推理进行精细控制。开发人员可以进行微调:
- 解码方法:选择使用哪种解码策略。
- 温度设置:控制模型的输出,决定输出是更随机、更有创意还是更可预测。
- Top-p: 核采样4。
- 频率惩罚:根据新词元在文本中的现有频率对其进行惩罚。
- 最大词元限制:限制生成词元的数量。
此外,HailoRT还提供高级上下文管理。用户可以:
- 保存、加载和清除大型语言模型上下文
- 在不同对话之间切换
- 恢复对话中的聊天回复
- 在单一HEF文件中无缝交换不同的低秩适应适配器
推理工作流程
使用HailoRT GenAI推断大型语言模型包括三个简化步骤:
- 使用配置API将HEF模型传输到Hailo-10H的DRAM。
- 配置神经核,分配必要的内存资源。
- 准备就绪后,向模型发送输入提示并开始生成输出。
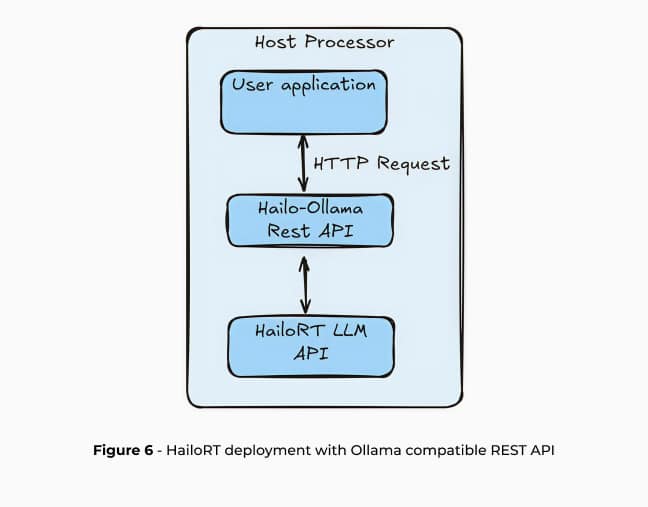
这些步骤可直接通过HailoRT或高级REST API与CPP API配合使用。HailoRT GenAI具有与Ollama和OpenAI兼容的REST API,可在Hailo-10H上实现无缝应用程序开发。这种集成缩小了复杂的人工智能基础设施与现实世界边缘人工智能部署之间的差距。
Ollama5 是一个开源项目,允许在本地部署大型语言模型,其简单的API可用于为各种应用创建、运行和管理大型语言模型模型,包括与Open-WebUI集成,提供用户友好的AI界面、RAGFlow(一个开源RAG引擎)和OpenCompass(允许人们轻松运行大型语言模型评估)。Ollama还与OpenAI和Anthropic等其他基于云的解决方案API兼容,从而确保轻松转换到边缘人工智能部署。
总结
大型语言模型(LLM)正在变革人工智能应用,但在边缘设备上部署这些模型却面临着与内存限制、计算效率和功耗相关的巨大挑战。Hailo-10H人工智能加速器通过创新的技术(如低秩适应)、先进的量化方法(QuaROT和GPTQ)以及全面的运行环境(HailoRT)来应对这些挑战。通过将整个大型语言模型管线卸载到专用加速器上,Hailo可以在边缘设备上实现高效、低功耗的大型语言模型推理,为开发人员提供强大的解决方案,用最低的计算开销将先进的人工智能功能引入个人电脑以及智能手机、汽车、物联网设备和嵌入式系统。展望未来,Hailo的路线图包括将这些功能扩展到专为镜头内应用而设计的Hailo-15H,将大型语言模型、视觉语言模型和其他生成式人工智能模型直接带到基于摄像头的系统。Hailo平台为各种硬件配置的边缘人工智能部署提供强大的解决方案,在效率、功耗限制和灵活性之间实现平衡,在包括大型语言模型、ASR、图像生成(稳定扩散)、视觉语言模型等在内的GenAI管线中提供广泛支持。
- 更多解释见https://www.youtube.com/watch?v=80bIUggRJf4 ↩︎
- QuaRot:旋转大型语言模型中的无异常4位推理 ↩︎
- GPTQ:生成式预训练转换器的精确后训练量化 ↩︎
- 更多解释见https://en.wikipedia.org/wiki/Top-p_sampling ↩︎
- 官方网站:https://ollama.com/ ↩︎