Hailo bietet bahnbrechende KI-Prozessoren, die speziell entwickelt wurden, um leistungsstarke Deep-Learning-Anwendungen auf Edge-Geräten zu ermöglichen.
Unsere Prozessoren sind auf die neue Ära der generativen KI am Rande der Welt ausgerichtet, parallel zur Ermöglichung von Wahrnehmung und Videoverbesserung durch unsere breite Palette von KI-Beschleunigern und Vision-Prozessoren.
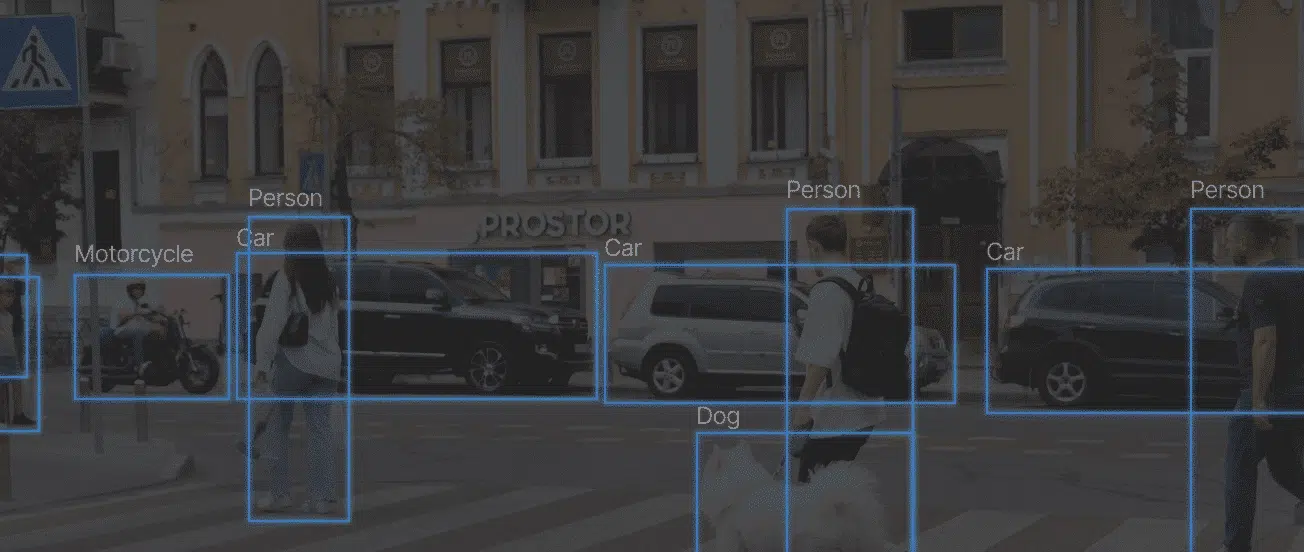
Co-Prozessoren, die sich in Edge-Plattformen integrieren lassen und Deep-Learning-Inferenzaufgaben in Echtzeit mit geringem Stromverbrauch und hoher Kosteneffizienz ermöglichen.
Unterstützung für eine breite Palette von neuronalen Netzen, Bildwandlermodellen und LLMs

Ich bin Thrive und den wunderbaren Technologien dankbar, die sie als Standardpaket anbieten. Die Einführung von Hailo macht es dann zu einem äußerst effektiven und einfach zu navigierenden System.

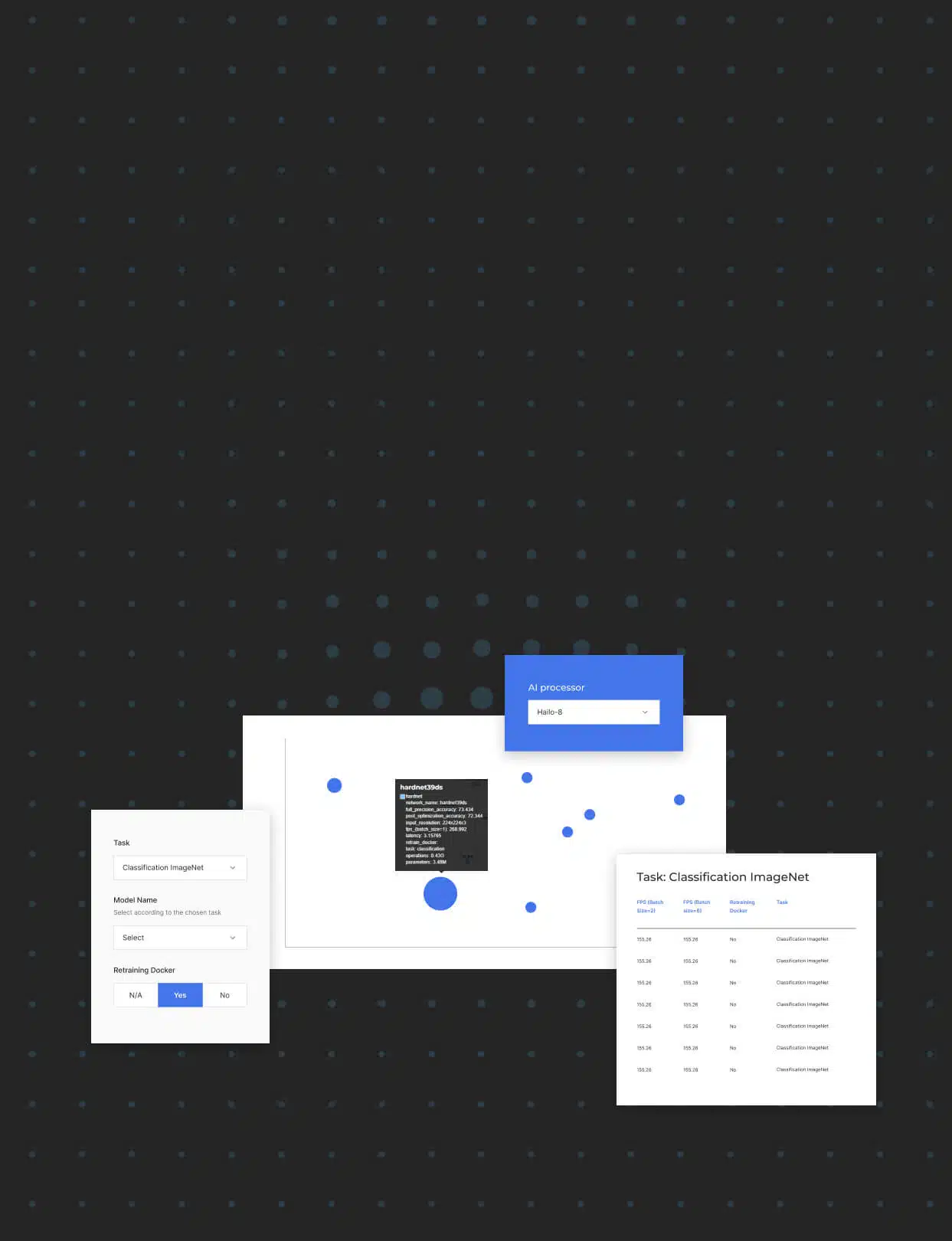
Die Umwandlung von KI-Modellen für denRandbereich Betrieb ist komplex und Hailo bietet eine stabile, gut durchdachte Plattform mit hervorragender Entwicklerunterstützung und Tools


Mit Hailo versorgen wirRandbereich-Geräte mit erneuerbaren Energien und erhalten immer noch mehr Funktionen für maschinelles Lernen als früher mit fest verdrahteten Labors


Hailo ermöglicht es uns, anspruchsvollere Operationen mit komplexeren Netzwerken durchzuführen und somit mehr Lösungen für die breite Palette von Herstellern anzubieten, mit denen wir zusammenarbeiten


Dieser Prozessor hilft uns, alle Einschränkungen zu überwinden


Hailo-8 erzielt im Vergleich zu herkömmlichen Produkten eine überwältigend hohe Leistung.