Generative KI vorantreiben: LLM am Beispiel von Hailo-10H

Einführung
Der Einsatz von großen Sprachmodellen (Large Language Models, LLMs) stellt die nächste Stufe bei der Nutzung fortschrittlicher künstlicher Intelligenz in ressourcenbeschränkten Umgebungen dar. Dieses Whitepaper befasst sich mit der Frage, wie Hailo-10H, ein fortschrittlicher KI-Beschleuniger, eine effiziente LLM Bereitstellung am Netzwerkrand ermöglicht und dabei hohe Leistung bietet und gleichzeitig die besonderen Herausforderungen hinsichtlich Speicherbeschränkungen, Energieeffizienz und Rechenbeschränkungen bewältigt. Durch innovative Optimierungstechniken, umfassende Toolchain-Unterstützung und spezialisierte Laufzeitumgebungen ermöglicht Hailo-10H Entwicklern, die Leistungsfähigkeit von LLMs in vielfältigen Edge-Anwendungen zu nutzen, ohne Kompromisse bei Leistung oder Genauigkeit eingehen zu müssen.
Was ist LLM?
Große Sprachmodelle (Large Language Models, LLMs) sind fortschrittliche neuronale Netze, die menschenähnliche Texte verarbeiten und generieren, indem sie Muster aus umfangreichen Datensätzen lernen. Sie werden häufig in kommerziellen Umgebungen für Anwendungen wie Chatbots im Kundenservice, automatisierte Inhaltserstellung, Sprachübersetzung und sogar Codegenerierung verwendet und treiben so die Innovation in verschiedenen Branchen voran.
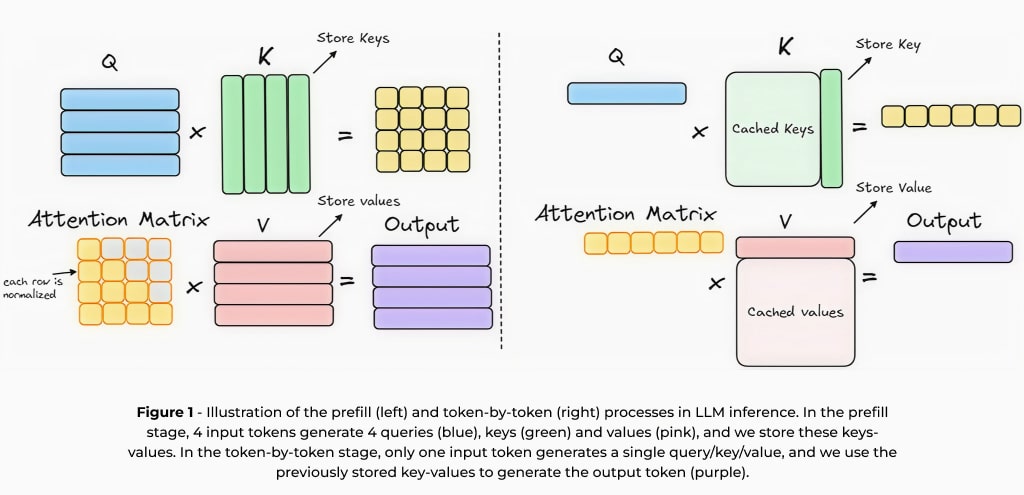
Im Kern basieren LLMs auf autoregressiven Architekturen, die Texte sequenziell generieren und jedes Wort auf der Grundlage des vorangegangenen Kontexts vorhersagen. Durch dieses Training zur Vorhersage des nächsten Wortes kann das Modell Sprachmuster lernen und kohärente Antworten generieren. Bei dieser Methode muss jedoch derselbe Kontext wiederholt verarbeitet werden, um neue Token zu erzeugen. Um die Inferenz zu beschleunigen, wird häufig ein Schlüsselwert-Cache (KV-Cache)1 verwendet, der Zwischenberechnungen aus vorherigen Tokens speichert, redundante Verarbeitungsprozesse reduziert und nachfolgende Vorhersagen beschleunigt. Die Inferenz mit dem KV-Cache umfasst zwei wichtige Schritte: (1) die Vorfüllphase, in der die Eingabeaufforderung verarbeitet und Zwischenberechnungen durchgeführt werden, und (2) die Generierungsphase, in der diese zwischengespeicherten Ergebnisse effizient genutzt werden, um Token sequenziell zu generieren.
Edge-Einsatz: Vorteile und Herausforderungen
Während cloudbasierte LLMs heute die meisten Anwendungen dominieren, bietet ihre Bereitstellung auf Edge-Geräten – wie Smartphones, Fahrzeugen, IoT-Geräten und eingebetteten Systemen – zahlreiche Vorteile. Dazu gehören geringere Latenzzeiten, verbesserter Datenschutz, geringere Kosten und eine höhere Ausfallsicherheit bei Verbindungsproblemen, wodurch eine kontextbezogene Verarbeitung in Echtzeit ohne Abhängigkeit von externen Servern ermöglicht wird. Andererseits bringt der Einsatz von LLM auf einem Edge-Gerät auch einzigartige Herausforderungen in Bezug auf Speicherbeschränkungen, Recheneffizienz und Stromverbrauch mit sich, die spezielle Hardware und Optimierungstechniken erfordern.
LLMs stellen aufgrund ihres hohen Speicherbedarfs erhebliche Herausforderungen dar. Beispielsweise benötigt ein Modell mit 1,5 Milliarden Parametern und einem 2K-Token-KV-Cache bei Verwendung von 4-Bit-Gewichten etwa 1,2 GB Speicher. Mit zunehmender Modellgröße wird die Optimierung der Speichernutzung zu einem entscheidenden Faktor für eine effiziente Bereitstellung, insbesondere auf Edge-Geräten. Techniken wie Quantisierung, die die Genauigkeit der Modellgewichte auf niedrigere Bit-Darstellungen reduziert, und die gemeinsame Nutzung von Gewichten zwischen den Vorfüll- und Token-für-Token-Generierungsphasen tragen dazu bei, den Speicherverbrauch zu minimieren und gleichzeitig die Leistung aufrechtzuerhalten. Solche Optimierungen sind entscheidend für den Einsatz von LLMs auf speicherbegrenzten Edge-Geräten, wobei sowohl Geschwindigkeit als auch Genauigkeit erhalten bleiben. Ein weiterer wichtiger Faktor für den Speicherbedarf ist die Kontextlänge. Beispielsweise erfordern jeweils 1 KB Tokens im Kontext zusätzliche 256 MB in Llama2-7B, wenn für Aktivierungen eine 8-Bit-Quantisierung verwendet wird, was im Gegensatz zur Cloud-Bereitstellung auch große Kontextlängen auf Edge-Geräten verhindert.
Leistungsmetriken und Bewertung
Zur Bewertung der LLM-Inferenzleistung werden in der Regel zwei Schlüsselkennzahlen verwendet: Time-to-First Token (TTFT) und Tokens-Per-Second (TPS). TTFT bezieht sich auf die Latenzzeit zwischen dem Absenden einer Eingabeaufforderung und dem Erhalt des ersten generierten Tokens, die stark von der Vorfüllphase und der Rechenleistung beeinflusst wird. Eine Verringerung der TTFT ist für Echtzeitanwendungen wie Sprachassistenten und Chatbots von entscheidender Bedeutung, da unmittelbare Antworten das Nutzererlebnis verbessern. Die TPS hingegen misst, wie schnell nachfolgende Token nach dem Erscheinen des ersten Tokens generiert werden, was sich direkt auf die Geläufigkeit und Reaktionsfähigkeit des Modells auswirkt. Eine höhere TPS sorgt für eine reibungslosere und flüssigere Texterstellung, was vor allem für KI- und Streaming-Anwendungen von Vorteil ist. Die Optimierung von TTFT und TPS ist eine wesentliche Voraussetzung für eine reibungslose und effiziente LLM-Leistung.
Da LLMs in verschiedenen Anwendungsfällen eingesetzt werden, wird die Bewertung ihrer Genauigkeit und der Vergleich verschiedener Modelle – oder die Beurteilung der Auswirkungen der Quantisierung – zu einer komplexen Aufgabe. Um eine umfassende Bewertung zu gewährleisten, werden in der Regel mehrere Datensätze und Metriken verwendet. Die Modelle können zum Beispiel auf die Beantwortung von Fragen zum Allgemeinwissen, auf codebezogene Aufgaben und auf die Genauigkeit der Zusammenfassung getestet werden. Diese Herausforderung ist auf Edge-Geräten noch ausgeprägter, da die Hardwarebeschränkungen die Modellgröße und Kontextlänge begrenzen. Im nächsten Abschnitt befassen wir uns mit der Low-Rank-Adaptation (LoRA), einer Technik zur effizienten Feinabstimmung von Modellen und ihrer Optimierung für eine bestimmte Aufgabe.
Was ist LoRA?
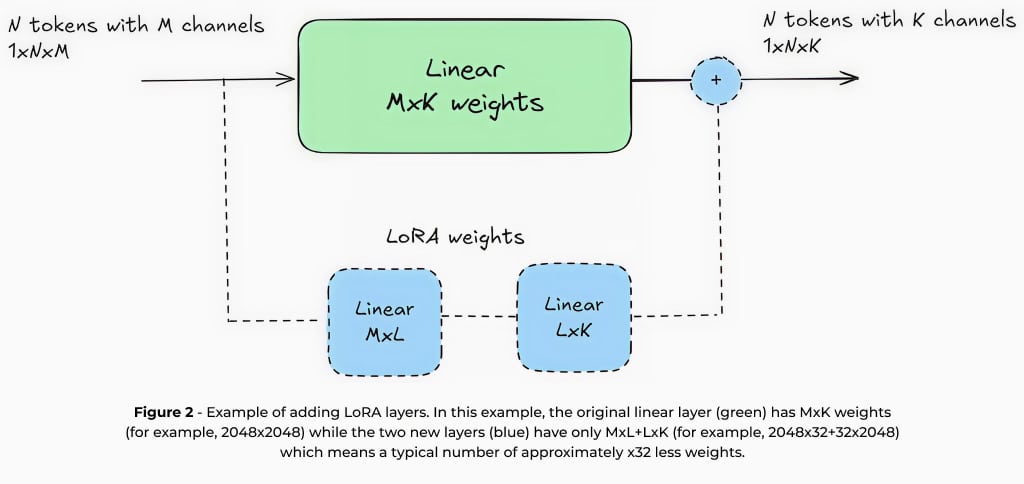
Das Training eines LLM von Grund auf ist ein aufwendiger und zeitintensiver Prozess, der erhebliche Rechenressourcen und eine spezialisierte Infrastruktur erfordert. Aus diesem Grund ist es üblich, effizientere Techniken zu verwenden, die vorab trainierte LLMs an bestimmte Anwendungsfälle anpassen und gleichzeitig das bereits während ihrer ersten Schulung erworbene Wissen nutzen. Die Low-Rank-Adaptation (LoRA) ist eine der am häufigsten verwendeten Methoden, um dies zu erreichen. LoRA funktioniert durch Hinzufügen kleiner trainierbarer Ebenen mit einer begrenzten Anzahl von Parametern, z. B. etwa 1–5 % des ursprünglichen Modells, während die Gewichte des Kernmodells unverändert bleiben.
Da LoRA nur eine kleine Teilmenge von Parametern aktualisiert, ermöglicht es eine Feinabstimmung mit relativ wenigen Daten und minimalen Rechenressourcen. Beispielsweise kann die Feinabstimmung eines LLM mit 7 Milliarden Parametern mithilfe von LoRA auf einer einzigen GPU durchgeführt werden, was es selbst für Unternehmen mit begrenzter Hardwareausstattung zu einer praktischen Lösung macht. Darüber hinaus erfordert LoRA in der Regel Datensätze, die nur Tausende von Beispielen enthalten, was den Aufwand und die Kosten für die domänenspezifische Anpassung erheblich reduziert.
Neben seiner Trainingseffizienz bietet LoRA deutliche Vorteile für den Edge-Einsatz. Da die meisten Modellgewichte unverändert bleiben, können mehrere LoRA-Adapter auf Geräten mit begrenztem Speicherplatz gespeichert und dynamisch ausgetauscht werden. Dadurch kann ein einziges Basismodell mehrere Aufgaben effizient und ohne übermäßigen Speicheraufwand ausführen. Eine intelligente Kamera könnte zum Beispiel ein Basismodell mit verschiedenen LoRA-Adaptern für Bildunterschriften, OCR und Kennzeichenerkennung verwenden. Zweitens ermöglicht die Feinabstimmung eines Modells für eine bestimmte Aufgabe, dass kleinere Modelle mit geringeren Rechenanforderungen eine hohe Genauigkeit erreichen – im Gegensatz zu großen cloudbasierten Modellen, die für eine allgemeine Verwendung konzipiert sind. Beispielsweise kann ein für die Zusammenfassung optimiertes Modell mit 1,5 Milliarden Parametern ein Allzweckmodell mit 7 Milliarden Parametern in seiner spezifischen Domäne übertreffen. Diese Vorteile machen LoRA zu einer unverzichtbaren Technik für den Einsatz von LLMs auf Edge-Geräten und helfen, die Lücke zwischen Ressourcenbeschränkungen und hochwertiger KI-Leistung zu schließen. In Hailo haben wir umfassende LoRA-Unterstützung in unsere Toolchain integriert, um eine klassenbeste Edge KI-Erfahrung für den LLM-Einsatz zu bieten. Dadurch können Entwickler Modelle effizient für bestimmte Anwendungsfälle anpassen und gleichzeitig eine optimale Leistung innerhalb der Leistungs- und Speicherbeschränkungen von Edge-Umgebungen gewährleisten.
Ausführen von LLM auf Hailo-10H
Hailo-10H ist ein fortschrittlicher AI-Beschleuniger, der für effiziente GenAI inferenz auf Edge-Geräten entwickelt wurde und eine hohe Leistung bei minimalem Stromverbrauch bietet. Die Hardware basiert auf dem einzigartigen neuronalen Kern von Hailo mit einem speziellen DRAM für den Beschleuniger. Hier konzentrieren wir uns auf LLMs, jedoch ist Hailo-10H in der Lage, viele weitere Modelle außerhalb des Rahmens dieses Artikels auszuführen, wie beispielsweise VLMs (Vision Language Models), Bildgenerierung, klassische Bildverarbeitungsmodelle und vieles mehr.
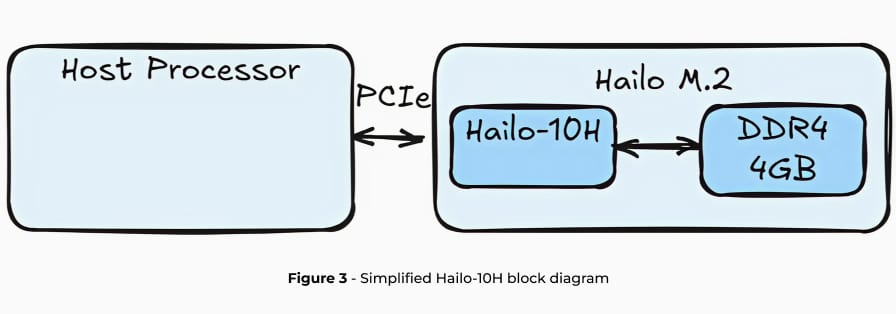
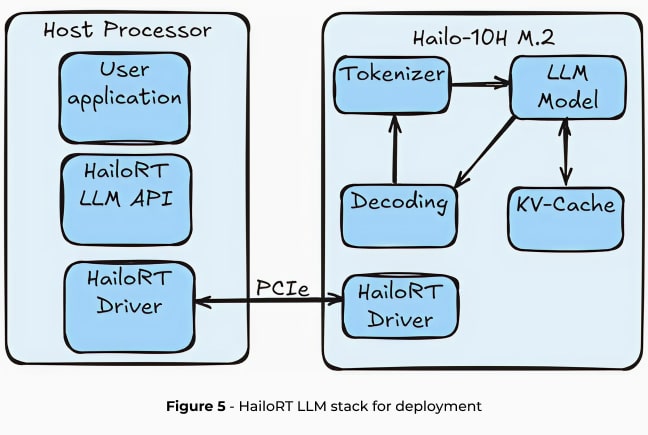
Bei der Ausführung von LLMs auf dem Hailo-10H wird die gesamte LLM-Pipeline auf den Beschleuniger ausgelagert, wobei die Auswirkungen auf die Auslastung des Host-Prozessors und die DRAM-Kapazität minimiert werden. In den nächsten beiden Abschnitten beschreiben wir die vollständige Toolchain von Hailo für die LLM-Bereitstellung, die LoRA-Unterstützung, Modelloptimierung und Kompilierung mit dem Hailo Dataflow Compiler (DFC) sowie Laufzeitbibliotheken und APIs für die einfache Bereitstellung auf dem Hailo-10H-Edge-Gerät über HailoRT bietet.
QWEN2-1.5B-Instruct |
Hailo-10H |
TTFT |
289ms for 96 input tokens |
TPS |
9.45 |
KV-cache |
2048 tokens (~1536 words) |
Memory requirement |
1.2GB |
Weight quantization scheme |
Static, 4-bit symmetric, group-wise |
Activation quantization scheme |
Static, 8-bit asymmetric, per-tensor |
KV-cache quantization scheme |
Static, 8-bit asymmetric, per-tensor |
HellaSwag |
↑66.06 / 64.3 (full precision/quantized) |
C4 |
↓14.38 / 15.1 (full precision/quantized) |
WikiText2 |
↓10.08 / 10.5 (full precision/quantized) |
Average power |
2.1W |
Table 1 – Evaluation metrics describing LLM inference on the Hailo-10H AI accelerator
LLMs im Dataflow Compiler
Der Weg zur Ausführung von LLM auf Hailo-10H beginnt mit dem Dataflow Compiler (DFC), einer leistungsstarken Optimierungs-Engine, die Standard-Sprachmodelle in Edge-Ready Powerhouses verwandelt.
Hailo nutzt zwei fortschrittliche Quantisierungsverfahren: QuaROT2 und GPTQ3 die mit der Modelloptimierungsstufe des Hailo Dataflow Compilers verschmolzen sind. QuaROT wendet eine Hadamard-Transformation auf Gewichtungsmatrizen an, wodurch Ausreißermerkmale in Aktivierungen gemildert und die Quantisierung insgesamt verbessert werden. Hailo implementiert QuaROT während der Optimierung ohne zusätzlichen Rechenaufwand für das eingesetzte Modell. GPTQ ergänzt dies, indem es eine einmalige Quantisierung nach dem Training ermöglicht, wobei die LLM-Gewichte unter Verwendung von Informationen zweiter Ordnung approximiert werden. Diese Techniken entwickeln sich de facto zu Industriestandards, die eine aggressive Quantisierung ermöglichen – beispielsweise eine gruppenweise 4-Bit-Gewichtungskomprimierung und 8-Bit für Aktivierungen – und gleichzeitig eine hohe Modellgenauigkeit gewährleisten.
Der Kompilierungsprozess beginnt mit einer voroptimierten Hailo Archive (HAR)-Datei, die mehr als nur ein Modell ist – sie ist ein umfassendes Bereitstellungspaket. Diese Datei enthält wichtige Komponenten wie Vorab- und Token-für-Token-Modellkonfigurationen, Schlüsselwert-Cache-Strukturen sowie das Wörterbuch und den Tokenizer des Modells. Die Benutzer erhalten eine einzige, vollständig optimierte Datei, die den gesamten Verteilungsworkflow optimiert.
Low-Rank Adaptation (LoRA) erweitert den Prozess um eine weitere Flexibilitätsebene. LoRA ist zwar fakultativ, ermöglicht es aber den Nutzern, bestimmte Modellebenen für eine bestimmte Leistung anzupassen. Die Toolchain unterstützt das iterative Hinzufügen von LoRA-Adaptern, wobei jeder Adapter unabhängig quantifiziert wird. LoRA-Gewichte können aus der umfangreichen Open-Source-Bibliothek von HuggingFace bezogen oder für bestimmte Anwendungsfälle individuell trainiert werden. Von der E-Mail-Zusammenfassung bis zur Codegenerierung können Entwickler Modelle für vielfältige Anwendungen optimieren.
Die Kompilierung gipfelt in der Erstellung einer Hailo Executable Format (HEF)-Datei – dem endgültigen Artefakt, das mit HailoRT auf dem Hailo-Gerät zur Inferenz bereitsteht. HailoRT bietet einen umfassenden API-Satz, der eine detaillierte Kontrolle über die LLM-Bereitstellung ermöglicht, einschließlich KV-Cache-Handling und Nachbearbeitungsparametern.

Einsatz von LLMs mit HailoRT GenAI
Die Hailo Runtime GenAI (HailoRT GenAI) bietet einen umfassenden API-Stack, der die LLM-Inferenz auf dem Hailo-10H vereinfacht. HailoRT wurde für eine nahtlose Integration entwickelt und unterstützt die Plattformen Linux, Windows und Android. Die Laufzeitumgebung bietet eine vollständige Abstraktion der LLM-Pipeline und übernimmt alles von der Tokenisierung bis zur endgültigen Tokenerzeugung ohne jegliche Host-Auslastung.
LLM-Inferenz-Pipeline
HailoRT GenAI unterteilt die LLM-Verarbeitung in vier kritische Phasen:
- Tokenisierung: Transformiert Eingabetext in einbettende Token und bereitet den Rohtext für die Verarbeitung durch ein neuronales Netzwerk. Der Tokenisierungsprozess wird in Rust mithilfe des Pakets „Hugging Face Tokenizers“ effizient implementiert.
- Modell-Inferenz: Ein Transformator-Decoder, der das nächste Token vorhersagt, indem er einen Wahrscheinlichkeitsvektor über den gesamten Wörterbuchraum generiert. Dieses Modell wird aus dem Kern des neuronalen Netzes von Hailo abgeleitet.
- Dekodierung: Interpretiert den Wahrscheinlichkeitsvektor des Modells, um das nächste Token in der Sequenz zu erzeugen.
- Key-Value Caching: Stores intermediate computational results, dramatically optimizing inference speed by eliminating redundant calculations.
Die gesamte Pipeline wird auf den Hailo-10H ausgelagert, wodurch die Auslastung des Host-Prozessors und der Modellspeicher auf ein vernachlässigbares Maß reduziert werden. Dieser Ansatz gewährleistet minimale Auswirkungen auf die CPU-Auslastung und DRAM-Kapazität, wodurch die Bereitstellung von Edge-KI wirklich ressourcenschonend wird.
Flexible Konfiguration und Steuerung
HailoRT GenAI bietet eine detaillierte Kontrolle über die LLM-Inferenz durch ein umfangreiches Konfigurations-Interface. Die Entwickler können eine Feinabstimmung vornehmen:
- Decoding methods: select which decoding strategy would be used.
- Temperature settings: control the model’s output and determine whether it will be more random and creative or more predictable.
- Top-p: Kernprobenahme4.
- Häufigkeitsstrafen: Neue Tokens werden basierend auf ihrer Häufigkeit im Text bestraft.
- Maximale Token-Limits: Begrenzen Sie die Anzahl der generierten Tokens.
Darüber hinaus bietet HailoRT eine erweiterte Kontextverwaltung. Benutzer können:
- Speichern, Laden und Löschen von LLM-Kontexten
- Zwischen verschiedenen Gesprächen wechseln
- Chat-Antworten aus der Mitte des Gesprächs fortsetzen
- Nahtloszwischen verschiedenen LoRA-Adaptern innerhalb einer einzigen HEF-Datei wechseln
Inferenz-Workflow
Die Ableitung eines LLM mit HailoRT GenAI umfasst drei rationalisierte Schritte:
- Übertragen Sie das HEF-Modell mithilfe der API configure in den DRAM des Hailo-10H.
- Konfigurieren Sie den neuronalen Kern und weisen Sie die erforderlichen Speicherressourcen zu.
- Danach senden Sie die Eingabeaufforderung an das Modell und beginnen mit der Generierung der Ausgabe.
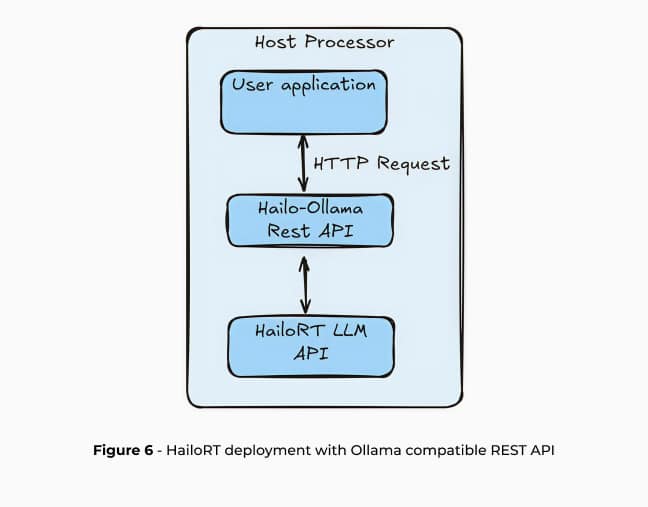
Diese Schritte können mit einer CPP-API direkt über HailoRT oder über eine High-Level-REST-API verwendet werden. HailoRT GenAI verfügt über eine REST-API, die mit Ollama und OpenAI kompatibel ist und eine nahtlose Anwendungsentwicklung auf dem Hailo-10H ermöglicht. Diese Integration schlägt eine Brücke zwischen komplexer KI-Infrastruktur und der praktischen Umsetzung von Edge-KI.
Ollama5 ist ein Open-Source-Projekt, das die lokale Bereitstellung von LLMs mit einer einfachen API zum Erstellen, Ausführen und Verwalten von LLM-Modellen für eine Vielzahl von Anwendungen ermöglicht, einschließlich der Integration mit Open-WebUI für eine benutzerfreundliche KI-Schnittstelle, RAGFlow, einer Open-Source-RAG-Engine, und OpenCompass, mit dem Sie LLM-Bewertungen einfach ausführen können.Ollama ist auch mit anderen Cloud-basierten Lösungs-APIs wie OpenAI und Anthropic kompatibel, was einen einfachen Übergang zum Einsatz von Edge AI gewährleistet.
Zusammenfassung
Große Sprachmodelle (LLMs) revolutionieren KI-Anwendungen, doch ihre Bereitstellung auf Edge-Geräten stellt erhebliche Herausforderungen hinsichtlich Speicherbeschränkungen, Recheneffizienz und Stromverbrauch dar. Der Hailo-10H KI-Beschleuniger löst diese Herausforderungen durch innovative Techniken wie Low-Rank Adaptation (LoRA), fortschrittliche Quantisierungsmethoden (QuaROT und GPTQ) und eine umfassende Laufzeitumgebung (HailoRT). Durch die Auslagerung der gesamten LLM-Pipeline auf einen dedizierten Beschleuniger ermöglicht Hailo eine effiziente LLM-Inferenz mit geringem Stromverbrauch auf Edge-Geräten und bietet Entwicklern eine leistungsstarke Lösung, um fortschrittliche KI-Funktionen mit minimalem Rechenaufwand auf PCs, Smartphones, Fahrzeuge, IoT-Geräte und eingebettete Systeme zu bringen. Für die Zukunft plant Hailo, diese Funktionen auf Hailo-15H auszuweiten, das speziell für kamerainterne Anwendungen entwickelt wurde, um LLM, VLM und andere generative KI-Modelle direkt in kamerabasierte Systeme zu integrieren. Die Hailo-Plattform bietet eine robuste Lösung für den Einsatz von Edge-KI in einer Vielzahl von Hardwarekonfigurationen und vereint Effizienz, Leistungsbeschränkungen und Flexibilität mit umfassender Unterstützung für GenAI-Pipelines, darunter LLM, ASR, Bildgenerierung (stabile Diffusion), VLM und vieles mehr.
- Weitere Erläuterungen finden Sie unter: https://www.youtube.com/watch?v=80bIUggRJf4 ︎ ↩︎
- QuaRot: Ausreißerfreie 4-Bit-Inferenz in rotierten LLMs ↩︎
- GPTQ: Genaue Quantisierung nach dem Training für generative vortrainierte Transformatoren ↩︎
- Weitere Erläuterungen finden Sie unter: https://en.wikipedia.org/wiki/Top-p_sampling ↩︎
- Offizielle Website: https://ollama.com/ ↩︎